In this post, we present an interlacing property of order statistics.
Suppose we have a distribution 
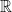
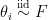

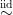
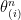


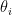
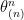



The ordered variables 
Theorem 1 For any
,
and
, we have
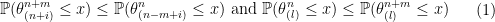

The meaning of the right inequalities of the inequality (1) and the inequality (2) is that the larger the sample size 

The first inequality chain is the stochastic dominance version of the second inequality chain. The first chain is a stronger property than the second.
Let us now explain why we call Theorem 1 an interlacing property. Consider the case that 
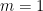

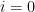

If 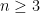
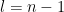


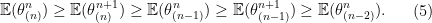
Continuing the choices of 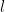


Thus we see the quantities 

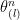


Proof: Let us first prove the right inequality. Suppose we first generate 

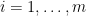
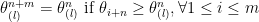
and

Since we have almost sure inequality, we surely have stochastic dominance and inequality in expectation. Now consider the left inequality. We still follow the previous ways of generating 


and

Thus we have shown that we have stochastically dominance for the random variables we are considering. The proof here is a bit lengthy and maybe not so clear but correct. One may draw a picture of the data-generating process and then compare the

Interestingly, the above proof actually did not use the assumption that
Theorem 2 Let
have joint distribution
. Denote
to be the order statistics. Now consider only the first
. Denote their marginal distribution as
. We denote the order statistics of these
. Then for any
and

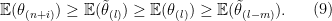
Proof: The proof is a repetition of the previous argument. Let us first prove the middle inequality of (8) and (9). Suppose we first generate 



We now consider all the 
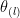
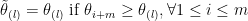
and

Since we have almost sure inequality, we surely have stochastic dominance and inequality in expectation. Now consider the right-most inequality of (8) and (9). . We still follow the previous ways of generating 

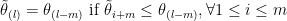
and

Thus we have shown that we have stochastically dominance for the random variables we are considering. The left-most inequality of of (8) and (9) can be proved using the fact that 
I found this interlacing result while taking a take-home exam on game theory. It turns out this result is not useful for the exam though. I would also like to thank Yueyang Liu for capturing a mistake in the previous version of the post.
 with parameter (index)
with parameter (index)  is said to be a natural exponential family if
is said to be a natural exponential family if  can be written as
can be written as
 , we call
, we call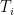 : natural sufficient statistic
: natural sufficient statistic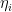 : natural parameter
: natural parameter : natural parameter space.
: natural parameter space.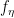 ,
, 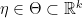 , and a random variable
, and a random variable  , a statistic
, a statistic 
 is independent of
is independent of  . A sufficient statistic
. A sufficient statistic  , there is a function
, there is a function  such that
such that  .
. according to
according to  ! So even though you don’t know the underlying distribution
! So even though you don’t know the underlying distribution  is
is .
.
 .
.
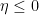 for the integral
for the integral  to be finite and
to be finite and  for the integral
for the integral  to be finite. This means actually
to be finite. This means actually  and so the natural parameter space is a single point
and so the natural parameter space is a single point  .
. is indeed sufficient. But any constant estimator is also sufficient and minimal as any other sufficient statistic under a constant function is a constant. But
is indeed sufficient. But any constant estimator is also sufficient and minimal as any other sufficient statistic under a constant function is a constant. But 