In this post, we study a few probability one results conerning the rank of random matrices: with probability one,
- a random asymmetric matrix has full rank;
- a random symmetric matrix has full rank;
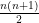 many random rank one positive semidefinite matrices (belonging to
many random rank one positive semidefinite matrices (belonging to  ) are linearly independent.
) are linearly independent.
At least for the first two, they look quite natural and should be correct at first glance. However, to rigorously prove them does require some effort. The post is trying to show that one can use the concept of independence to prove the above assertions. Indeed, all the proof follows an inductive argument where independence makes life much easier:
- Draw the first sample, it satisfies the property we want to show,
- Suppose first
 samples satisfy the property we want to show, draw the next sample. Since it is independent of the previous samples, the first samples can be considered as fixed. Then we make some effort to say the first
samples satisfy the property we want to show, draw the next sample. Since it is independent of the previous samples, the first samples can be considered as fixed. Then we make some effort to say the first  sample does satisfy the property.
sample does satisfy the property.
Before we going into each example, we further note for any probability measure that is absolutely continuous respect to the measure introduced below and vice versa (so independence is not needed), the probability  results listed above still hold.
results listed above still hold.
1. Random Matrices are full rank
Suppose 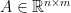 with
with ![{A=[a_{ij}]}](https://s0.wp.com/latex.php?latex=%7BA%3D%5Ba_%7Bij%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and each entry of
and each entry of  is drawn independently from standard Gaussian
is drawn independently from standard Gaussian 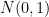 . We prove that
. We prove that  has rank
has rank  with probability .
with probability .
To start, we should assume without loss of generality that  . Otherwise, we just repeat the following argument for
. Otherwise, we just repeat the following argument for  .
.
The trick is to use the independence structure and consider columns of are drawn from left to right. Let’s write the  -th column of by
-th column of by 
For the first column, we know  is linearly independent because it is
is linearly independent because it is  with probability . For the second column, because it is drawn independently from the first column, we can consider the first column is fixed, and the probability of
with probability . For the second column, because it is drawn independently from the first column, we can consider the first column is fixed, and the probability of  fall in to the span of a fixed column is because has a continuous density in
fall in to the span of a fixed column is because has a continuous density in 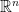 . Thus the first two columns are linearly independent.
. Thus the first two columns are linearly independent.
For general 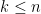 , because , we know the first
, because , we know the first 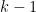 columns forms a subspace in and so
columns forms a subspace in and so 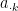 falls into that subspace with probability (linear subspace has Lebesgue measure in and Gaussian measure is absolutely continuous with respect to Lebesgue measure and vice versa). Thus we see first columns are linearly independent. Proceeding the argument until
falls into that subspace with probability (linear subspace has Lebesgue measure in and Gaussian measure is absolutely continuous with respect to Lebesgue measure and vice versa). Thus we see first columns are linearly independent. Proceeding the argument until 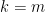 completes the proof.
completes the proof.
2. Symmetric Matrices are full rank
Suppose 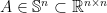 with and each entry of the upper half of ,
with and each entry of the upper half of , 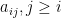 , is drawn independently from standard Gaussian . We prove that has rank
, is drawn independently from standard Gaussian . We prove that has rank  .
.
Let’s write the -th row of by 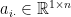 . For the first entries of the -th row, we write
. For the first entries of the -th row, we write 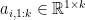 . Similarly,
. Similarly,  denotes the first entries of the -th column. For the top left
denotes the first entries of the -th column. For the top left  submatrix of , we denote it by
submatrix of , we denote it by  . Similar notation applies to other submatrices.
. Similar notation applies to other submatrices.
The idea is drawing each column of from left to right sequentially and using the independence structure. Starting from the first column, with probability one, we have that is linearly independent (meaning  ).
).
Now since is drawn and the second column except the first entry is independent of , we know it is in the span of if the second column is  (
(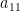 is with probability 0) multiple of . This still happens with probability since each entry of
is with probability 0) multiple of . This still happens with probability since each entry of  has continuous probability density and is drawn independently from .
has continuous probability density and is drawn independently from .
Now assume we have drawn the first columns of , the first columns are linearly independent with probability , and the left top submatrix of is invertible (the base case is what we just proved). We want to show after we draw the column, the first columns are still linearly independent with probability . Since the first columns is drawn, the first entries of the column  is fixed, we wish to show the rest
is fixed, we wish to show the rest 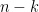 entries which are drawn independently from all previous columns will ensure linearly independence of first columns.
entries which are drawn independently from all previous columns will ensure linearly independence of first columns.
Suppose instead is linearly dependent with first columns of . Since the left top submatrix of is invertible, we know there is only one way to write as a linear combination of previous columns. More precisely, we have

This means has to be a fixed vector which happens with probability because the last entries of is drawn independently from , 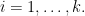 Note this implies that the first columns of are linearly independent as well as the left top
Note this implies that the first columns of are linearly independent as well as the left top  submatrix of is invertible because we can repeat the argument simply by thinking is (instead of
submatrix of is invertible because we can repeat the argument simply by thinking is (instead of 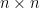 ). Thus the induction is complete and we prove indeed has rank with probability .
). Thus the induction is complete and we prove indeed has rank with probability .
3. Rank positive semidefinite matrices are linearly independent
This time, we consider 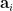 ,
,  are drawn independently from standard normal distribution in . Denote the set of symmetric matrices in as
are drawn independently from standard normal distribution in . Denote the set of symmetric matrices in as 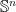 . We show that with probability the matrices
. We show that with probability the matrices

are linearly independent in .
Denote the standard -th basis vector in as 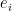 . First, let us consider the following basis (which can be verified easily) in ,
. First, let us consider the following basis (which can be verified easily) in ,

We order the basis according to the lexicographical order on 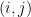 . Suppose
. Suppose 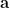 follows standard normal distribution in , we prove that for any fixed linear subspace
follows standard normal distribution in , we prove that for any fixed linear subspace  with dimension less than , we have
with dimension less than , we have

We start by applying an fixed invertible linear map  to
to  so that the basis of
so that the basis of 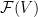 is the first
is the first  many basis vector of
many basis vector of 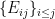 ({in lexicographical order.}), and the basis of the orthogonal complement (defined via the trace inner product) of ,
({in lexicographical order.}), and the basis of the orthogonal complement (defined via the trace inner product) of ,  , is mapped to the rest of the basis vector of under
, is mapped to the rest of the basis vector of under  . We then only need to prove
. We then only need to prove

We prove by contradiction. Suppose  . It implies that there exists infinitely many
. It implies that there exists infinitely many 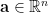 such that
such that 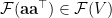 . Moreover, each component of takes infinitely many values. We show such situation cannot occur. Denote the
. Moreover, each component of takes infinitely many values. We show such situation cannot occur. Denote the  -th largest element in
-th largest element in 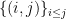 as
as  . Since has dimension less than ,
. Since has dimension less than ,  contains nonzero element and so
contains nonzero element and so
![\displaystyle \mathcal{F}(\mathbf{a}\mathbf{a}^\top) \in \mathcal{F}(V) \iff [\mathcal{F}(\mathbf{a}\mathbf{a}^\top)]_{ij}=0,\quad \forall (i,j) > (i_0,j_0) \,\text{in lexicographical order.}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BF%7D%28%5Cmathbf%7Ba%7D%5Cmathbf%7Ba%7D%5E%5Ctop%29+%5Cin+%5Cmathcal%7BF%7D%28V%29+%5Ciff+%5B%5Cmathcal%7BF%7D%28%5Cmathbf%7Ba%7D%5Cmathbf%7Ba%7D%5E%5Ctop%29%5D_%7Bij%7D%3D0%2C%5Cquad+%5Cforall+%28i%2Cj%29+%3E+%28i_0%2Cj_0%29+%5C%2C%5Ctext%7Bin+lexicographical+order.%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Now fix an  , we know
, we know ![{ [\mathcal{F}(\mathbf{a}\mathbf{a}^\top)]_{i_1j_1}=0}](https://s0.wp.com/latex.php?latex=%7B+%5B%5Cmathcal%7BF%7D%28%5Cmathbf%7Ba%7D%5Cmathbf%7Ba%7D%5E%5Ctop%29%5D_%7Bi_1j_1%7D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) means that there is some
means that there is some 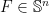 (depending only on ) such that
(depending only on ) such that

where  is the -th complement of . Now if we fix
is the -th complement of . Now if we fix 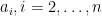 and only vary
and only vary 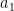 , then we have
, then we have

which holds for infinitely many 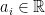 only if
only if
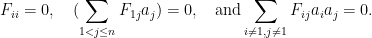
Thus we can repeat the argument as before and conclude that 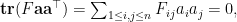 holds for infinitely many with each component taking infinitely many values only if
holds for infinitely many with each component taking infinitely many values only if  . This contradicts the fact that is invertible and hence we must have
. This contradicts the fact that is invertible and hence we must have
Now proving 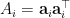 spans with probability is easy. Because for each , the
spans with probability is easy. Because for each , the 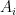 with
with  being drawn can be considered fixed because
being drawn can be considered fixed because  is drawn independently of . But the probability of stays in the span of
is drawn independently of . But the probability of stays in the span of  is by previous result and hence is linearly independent of all . This argument continues to hold for
is by previous result and hence is linearly independent of all . This argument continues to hold for  because the space spanned by
because the space spanned by 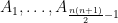 is at most
is at most 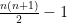 and so previous result applies. This completes the proof.
and so previous result applies. This completes the proof.
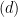




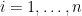

![\displaystyle \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right]. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)

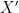
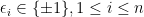
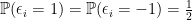
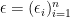
![\displaystyle \begin{aligned} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n f(X_i)- \mathbb{E}f(X_i) \right) \right] \\ \overset{(a)}{=} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n f(X_i)- \mathbb{E}_{X_i'}f(X_i') \right) \right] \\ \overset{(b)}{ =} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n \mathbb{E}_{X_i'}(f(X_i)-f(X_i')) \right) \right]\\ \overset{(c)}{\leq} & \mathbb{E}_{X,X'}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n (f(X_i)-f(X_i')) \right) \right]\\ \overset{(d)}{=} & \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n \epsilon_i(f(X_i)-f(X_i')) \right) \right]\\ \overset{(e)}{=} & \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]+ \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i') \right| \right]\\ \overset{(f)}{=} & 2 \mathbb{E}_{X,\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]. \end{aligned} \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+f%28X_i%29-+%5Cmathbb%7BE%7Df%28X_i%29+%5Cright%29+%5Cright%5D+%5C%5C+%5Coverset%7B%28a%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+f%28X_i%29-+%5Cmathbb%7BE%7D_%7BX_i%27%7Df%28X_i%27%29+%5Cright%29+%5Cright%5D+%5C%5C+%5Coverset%7B%28b%29%7D%7B+%3D%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb%7BE%7D_%7BX_i%27%7D%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28c%29%7D%7B%5Cleq%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28d%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28e%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D%2B+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%27%29+%5Cright%7C+%5Cright%5D%5C%5C+%5Coverset%7B%28f%29%7D%7B%3D%7D+%26+2+%5Cmathbb%7BE%7D_%7BX%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{ \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]}](https://s0.wp.com/latex.php?latex=%7B+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
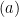

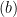
![{\mathbb{E}_{X'}[\cdot]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7BX%27%7D%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathbb{E}[ \cdot \mid X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B+%5Ccdot+%5Cmid+X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
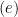
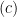

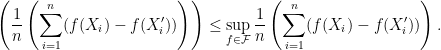
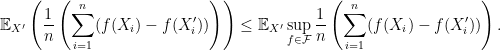

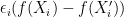
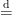


![\displaystyle [f_j(X_i)-f_j(X_i')]_{1\leq i\leq n,1\leq j\leq m} \overset{\text{d}}{=} \left[\epsilon_i \left(f_j(X_i)-f_j(X_i')\right)\right]_{1\leq i\leq n,1\leq j\leq m}. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+i%5Cleq+n%2C1%5Cleq+j%5Cleq+m%7D+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5Cleft%5B%5Cepsilon_i+%5Cleft%28f_j%28X_i%29-f_j%28X_i%27%29%5Cright%29%5Cright%5D_%7B1%5Cleq+i%5Cleq+n%2C1%5Cleq+j%5Cleq+m%7D.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle [f_j(X_i) - f_j(X_i')]_{j=1}^m \overset{\text{d}}{=} [\epsilon_i (f_j(X_i) - f_j(X_i'))]_{j=1}^m,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bf_j%28X_i%29+-+f_j%28X_i%27%29%5D_%7Bj%3D1%7D%5Em+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5B%5Cepsilon_i+%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![[\epsilon_i (f_j(X_i) - f_j(X_i'))]_{j=1}^m = \epsilon_i [(f_j(X_i) - f_j(X_i'))]_{j=1}^m.](https://s0.wp.com/latex.php?latex=%5B%5Cepsilon_i+%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em+%3D+%5Cepsilon_i+%5B%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em.+&bg=ffffff&fg=000000&s=0&c=20201002)
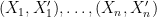
![\displaystyle [[f_j(X_i)-f_j(X_i')]_{1\leq j\leq m}]_{1\leq i\leq n} \overset{\text{d}}{=} [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)



![\displaystyle \begin{aligned} &\mathbb{P}( [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B)\\ \overset{(a)}{=}& \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B | \epsilon = \bar{\epsilon})\\ \overset{(b)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\bar{\epsilon}_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B | \epsilon = \bar{\epsilon})\\ \overset{(c)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\bar{\epsilon}_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B )\\ \overset{(d)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B )\\ =& \mathbb{P}( [[(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B ). \end{aligned} \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26%5Cmathbb%7BP%7D%28+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B%29%5C%5C+%5Coverset%7B%28a%29%7D%7B%3D%7D%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%7C+%5Cepsilon+%3D+%5Cbar%7B%5Cepsilon%7D%29%5C%5C+%5Coverset%7B%28b%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cbar%7B%5Cepsilon%7D_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%7C+%5Cepsilon+%3D+%5Cbar%7B%5Cepsilon%7D%29%5C%5C+%5Coverset%7B%28c%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cbar%7B%5Cepsilon%7D_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29%5C%5C+%5Coverset%7B%28d%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29%5C%5C+%3D%26+%5Cmathbb%7BP%7D%28+%5B%5B%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)

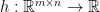
![\displaystyle \mathbb{E}\left[h\left([f_j(X_i)-f_j(X_i')]_{1\leq j\leq m, \;1\leq i\leq n} \right)\right] = \mathbb{E}\left[h\left(\left[\epsilon_i(f_j(X_i)-f_j(X_i'))\right]_{1\leq j\leq m, \;1\leq i\leq n} \right)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft%5Bh%5Cleft%28%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+j%5Cleq+m%2C+%5C%3B1%5Cleq+i%5Cleq+n%7D+%5Cright%29%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5Bh%5Cleft%28%5Cleft%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5Cright%5D_%7B1%5Cleq+j%5Cleq+m%2C+%5C%3B1%5Cleq+i%5Cleq+n%7D+%5Cright%29%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

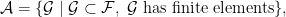
![\displaystyle \begin{aligned} \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right] := \sup_{\mathcal{G}\in \mathcal{A}} \mathbb{E}\left [ \sup_{f\in \mathcal{G}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right]. \end{aligned} \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D+%3A%3D+%5Csup_%7B%5Cmathcal%7BG%7D%5Cin+%5Cmathcal%7BA%7D%7D+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BG%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
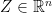 and we know that
and we know that  only takes value in a convex set
only takes value in a convex set  , i.e.,
, i.e.,
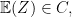
 exists. It is then natural to ask how about conditional expectation. Is it true for any reasonable sigma-algebra
exists. It is then natural to ask how about conditional expectation. Is it true for any reasonable sigma-algebra 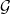 that
that
 , and for any probability measure
, and for any probability measure  on
on  with
with
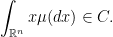
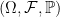 to
to 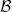 is the usual Borel sigma algebra on
is the usual Borel sigma algebra on 

 .
. such that for almost all
such that for almost all 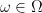 , we have for any
, we have for any 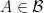

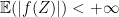 , we have
, we have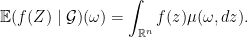
 and
and  , we have for almost all
, we have for almost all  ,
,
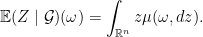
 , we know that for almost all
, we know that for almost all 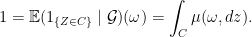
 we have a probability distribution
we have a probability distribution 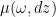 on
on  with mean equals to
with mean equals to 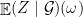 and
and  . This is exactly the situation of Theorem
. This is exactly the situation of Theorem 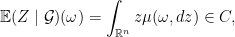

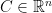 such that
such that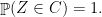

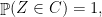

 and
and  where
where 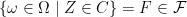 or
or  is understood as
is understood as  is a measurable event with respect to the completed measure space
is a measurable event with respect to the completed measure space  and we overload the notation
and we overload the notation  to mean
to mean  . The probability space
. The probability space  are convex sets in
are convex sets in 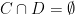 , then there exists a nonzero
, then there exists a nonzero  such that
such that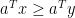
 .
.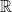 is always an interval.
is always an interval. dimension in
dimension in 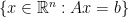 for some
for some 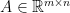 and
and  .
. is not in
is not in  such that
such that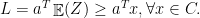
 almost surely, we should have
almost surely, we should have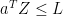
 , we see that
, we see that  with probability
with probability  and
and  dimensional affine space.
dimensional affine space. . After a proper translation and rotation, we can say that
. After a proper translation and rotation, we can say that 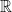 and we want to argue that the mean of
and we want to argue that the mean of  , we should have its mean in the interval. If the interval is half open and half closed and if the means is not in the interval, then
, we should have its mean in the interval. If the interval is half open and half closed and if the means is not in the interval, then 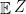 must be the open end of the interval since expectation preserves order, but this means that
must be the open end of the interval since expectation preserves order, but this means that  . This completes the proof.
. This completes the proof.  to a measurable space
to a measurable space  where each singleton set of
where each singleton set of  is in
is in 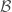 . Let each
. Let each  be a real valued (Borel measurable) function with its domain to be
be a real valued (Borel measurable) function with its domain to be 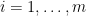 . Given
. Given
 such that
such that  takes no more than
takes no more than 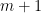 values in
values in 
 , then just ignore these. I put these term here just to make sure the that the theorem is rigorous enough.)
, then just ignore these. I put these term here just to make sure the that the theorem is rigorous enough.) with its first
with its first 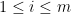


 and
and  .
. and its all
and its all 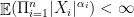
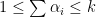 . Each
. Each 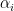 here is a nonnegative integer. The total number of moments in this case is
here is a nonnegative integer. The total number of moments in this case is  . Then there is a real random vector
. Then there is a real random vector  such that it takes no more than
such that it takes no more than  values, and
values, and
 , and any random variable
, and any random variable 

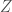 takes only finitely many value. But it is true that
takes only finitely many value. But it is true that 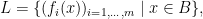
 is
is
 which takes value only in
which takes value only in  , by Lemma
, by Lemma 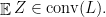
 has a FINITE representation in terms of
has a FINITE representation in terms of 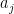 s!
s!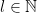 ,
, 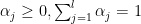 and
and  such that
such that
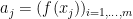 for some
for some 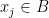 , we can simply take the distribution of
, we can simply take the distribution of 
 .
. 