Suppose we have a general optimization problem.

Also, suppose problem (1) has a minimum and the minimum can be achieved by a unique minimizer  .
.
Now if I have a point  such that
such that  is very small, then how small is the distance
is very small, then how small is the distance  . We might expect that
. We might expect that  will imply that
will imply that 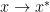 . This is true if
. This is true if  is compact and
is compact and  is continuous. But this does not tell what is the quantitative relationship between the optimal gap, i.e.,
is continuous. But this does not tell what is the quantitative relationship between the optimal gap, i.e.,  , and the distance to the solution, i.e., .
, and the distance to the solution, i.e., .
In this post, I am going to show that for linear programming (LP), the optimal gap and distance to solutions are the same up to a multiplicative constant which only depends on the problem data.
To start, consider an LP in the standard form, i.e.,
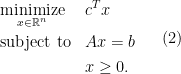
where the decision variable is and problem data are  .
. 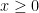 means each coordinate of is nonnegative.
means each coordinate of is nonnegative.
Denote the solution set of problem (1) to be 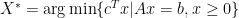 , and the distance to the solution set
, and the distance to the solution set 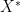 to be
to be 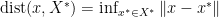 . Note that the norm here is arbitrary, not necessarily the Euclidean norm.
. Note that the norm here is arbitrary, not necessarily the Euclidean norm.
We are now ready to state the theorem.
Theorem 1 (Sandwich inequality of optimal gap and distance to solutions of LP) For problem (1), theres exist constants  which depends only on
which depends only on 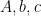 and
and 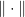 such that for all feasible , i.e.,
such that for all feasible , i.e.,  ,
,

The above theorem shows that the role of optimal gap, i.e., 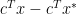 , and the distance to the solution set, i.e.
, and the distance to the solution set, i.e.  , are the same up to a multiplicative constant. The right inequality of the theorem is usually referred to as linear growth in the optimization literature.
, are the same up to a multiplicative constant. The right inequality of the theorem is usually referred to as linear growth in the optimization literature.
The proof below is constructive and we can in fact take 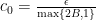 where
where  and
and  for
for  and
and  . Here
. Here  is the dual norm and
is the dual norm and  are extreme points and extreme rays. We assume there are
are extreme points and extreme rays. We assume there are  many extreme points and
many extreme points and  many extreme rays with first
many extreme rays with first  s and first
s and first 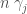 are in the optimal set
are in the optimal set 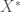 . See the proof for more detail.
. See the proof for more detail.
The idea of the proof mainly relies on the extreme point and extreme rays representation of the feasible region and the optimal set,i.e., 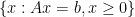 and .
and .
Proof: The feasible region can be written as
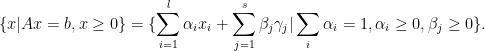
Here  s are extreme points of the feasible region and
s are extreme points of the feasible region and  s are extreme rays. By scaling the extreme rays, we can assume that
s are extreme rays. By scaling the extreme rays, we can assume that  for all
for all  .
.
The optimal set can also be written as

We assume here the first  many and
many and  many are in the optimal set and the rest of and s are not for notation simplicity.
many are in the optimal set and the rest of and s are not for notation simplicity.
We denote  and where . Note
and where . Note  since the s not in the optimal set should have inner product with
since the s not in the optimal set should have inner product with  to be positive.
to be positive.
We first prove the second inquality, i.e.,  .
.
Now take an arbitrary feasible , it can be written as

for some  and
and  .
.
The objective value of is then

We use the fact that  for all
for all  here.
here.
Subtract the above by  . We have
. We have

The second equality is due to  and the inequality is because of the definition of
and the inequality is because of the definition of  and the
and the  s are positive.
s are positive.
The distance between and is the infimum of

By taking  with
with  and
and 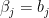 and apply triangular inequality to the above quantity, we have
and apply triangular inequality to the above quantity, we have

The first inequality is the triangular inequality and  . The second inequality is applying the definition of
. The second inequality is applying the definition of  and
and  . The first equality is due to
. The first equality is due to 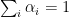 and the second equality is due to .
and the second equality is due to .
Thus the distance between and is bounded above by
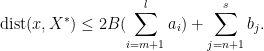
Since  by our previous argument, we see that setting
by our previous argument, we see that setting

should give us

We now prove the inequality
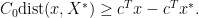
Note that the infimum in is actually achieved by some . The reason is that we can first pick a  , then
, then
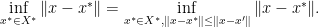
But the set 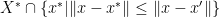 is actually bounded and closed ( is closed as it is a convex combination of finite points plus a conic combination of extreme vectors), thus Weierstrass theorems tells us that the infimum is actually achieved by some
is actually bounded and closed ( is closed as it is a convex combination of finite points plus a conic combination of extreme vectors), thus Weierstrass theorems tells us that the infimum is actually achieved by some  .
.
Now take such that 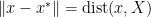 . We have
. We have

where  is the dual norm of . Thus letting finishes the proof.
is the dual norm of . Thus letting finishes the proof. 
From the proof, we see that two possible choice of 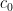 and
and 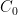 are where and for and . These are not optimal and can be sharpened. I probably will give a sharper constant in a future post.
are where and for and . These are not optimal and can be sharpened. I probably will give a sharper constant in a future post.


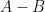

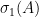
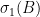
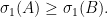
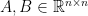
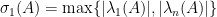



are all nonnegative and symmetric, then


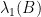
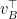




are all nonnegative, then






 , a convex function
, a convex function 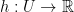 where
where 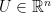 is a convex set and an
is a convex set and an 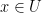 , if
, if  or
or  , then
, then![\displaystyle \begin{aligned} \partial (\phi \circ h) (x) = \phi' (h(x)) \cdot[ \partial h (x)], \end{aligned} \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cpartial+%28%5Cphi+%5Ccirc+h%29+%28x%29+%3D+%5Cphi%27+%28h%28x%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
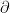 is the operator of taking subdifferentials of a function, i.e.,
is the operator of taking subdifferentials of a function, i.e., 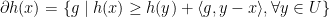 for any
for any  is the interior of
is the interior of  with respect to the standard topology in
with respect to the standard topology in  .
.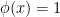 for all
for all  and
and 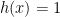 defined on
defined on ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then
. Then  is a point which is not in the interior of
is a point which is not in the interior of ![{[0,1],\phi'(0) = 0}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%2C%5Cphi%27%280%29+%3D+0%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![{\partial h(0) =(-\infty,0]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+h%280%29+%3D%28-%5Cinfty%2C0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . However, in this case
. However, in this case ![{\partial (\phi\circ h)(0)= (-\infty,0]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+%28%5Cphi%5Ccirc+h%29%280%29%3D+%28-%5Cinfty%2C0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{\phi' (h(0)) \cdot[ \partial h (0)] =0}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%27+%28h%280%29%29+%5Ccdot%5B+%5Cpartial+h+%280%29%5D+%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Thus, the equality fails.
. Thus, the equality fails. is also differentiable, then the above reduces to the common chain rule of smooth functions.
is also differentiable, then the above reduces to the common chain rule of smooth functions.![{\partial (\phi \circ h) (x) \supset \phi' (h(x)) \cdot[ \partial h (x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+%28%5Cphi+%5Ccirc+h%29+%28x%29+%5Csupset+%5Cphi%27+%28h%28x%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We have for all
. We have for all  ,
,
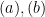 are just the definition of subdifferential of
are just the definition of subdifferential of  at
at  and
and  in the inequality
in the inequality 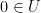 such that
such that 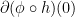 is not empty. Let
is not empty. Let 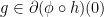 , we wish to show that
, we wish to show that  is in the set
is in the set ![{ \phi' (h(0)) \cdot[ \partial h (0)]}](https://s0.wp.com/latex.php?latex=%7B+%5Cphi%27+%28h%280%29%29+%5Ccdot%5B+%5Cpartial+h+%280%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . First according to the definition of subdifferential, we have
. First according to the definition of subdifferential, we have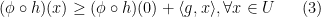
![\displaystyle \begin{aligned} (\phi \circ h) (\gamma x)\geq (\phi\circ h)(0) + \langle{ g} ,{\gamma x}\rangle, \forall x \in U, \gamma \in [0,1]. \end{aligned} \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%28%5Cphi+%5Ccirc+h%29+%28%5Cgamma+x%29%5Cgeq+%28%5Cphi%5Ccirc+h%29%280%29+%2B+%5Clangle%7B+g%7D+%2C%7B%5Cgamma+x%7D%5Crangle%2C+%5Cforall+x+%5Cin+U%2C+%5Cgamma+%5Cin+%5B0%2C1%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
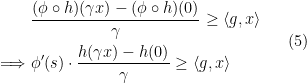
 between
between 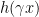 and
and 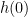 by mean value theorem. Now, by letting
by mean value theorem. Now, by letting 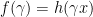 , if
, if  is nondecreasing in
is nondecreasing in  and we have
and we have 
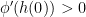 , then dividing both sides of the above inequality by
, then dividing both sides of the above inequality by 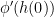 gives
gives 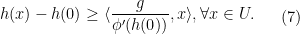
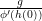 is indeed a member of
is indeed a member of 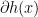 and thus
and thus ![{\partial (\phi \circ h) (x) \subset \phi' (h(x)) \cdot[ \partial h (x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+%28%5Cphi+%5Ccirc+h%29+%28x%29+%5Csubset+%5Cphi%27+%28h%28x%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . In this case, we only need to verify why
. In this case, we only need to verify why 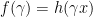 must be right continuous at
must be right continuous at 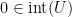 , then
, then 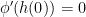 , using the inequality
, using the inequality 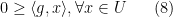
 , then
, then 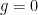 and it indeed belongs to the set
and it indeed belongs to the set ![{\phi' (h(0)) \cdot[ \partial h (x)] = \{0\}}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%27+%28h%280%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D+%3D+%5C%7B0%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as  for
for 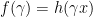 is indeed right continuous at
is indeed right continuous at  exists and
exists and  . Now if
. Now if  , then
, then 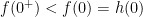 . But in this case
. But in this case 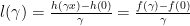 is going to be negative infinity as
is going to be negative infinity as  . Recall from inequality
. Recall from inequality 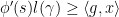
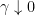 ,
, 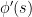 approaches a positive number. If this claim is true, then from the above inequality, we will have
approaches a positive number. If this claim is true, then from the above inequality, we will have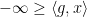
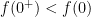 . Using mean value theorem, we have for some
. Using mean value theorem, we have for some ![{s_0 \in [ f(0^+), f(0)]}](https://s0.wp.com/latex.php?latex=%7Bs_0+%5Cin+%5B+f%280%5E%2B%29%2C+f%280%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
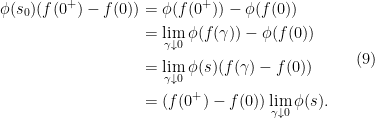
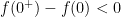 above, we see that
above, we see that  . We claim
. We claim 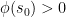 . If
. If 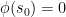 , then because
, then because ![{[f(0^+),f(0)]}](https://s0.wp.com/latex.php?latex=%7B%5Bf%280%5E%2B%29%2Cf%280%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as 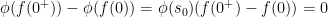 . This contradicts our assumption that
. This contradicts our assumption that  and our proof is complete.
and our proof is complete. ![{f:[0,1]\rightarrow \mathbb{R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5B0%2C1%5D%5Crightarrow+%5Cmathbb%7BR%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) be a (strictly) convex function, then the function
be a (strictly) convex function, then the function ![{g(x) = \frac{f(x)-f(0)}{x}, x\in(0,1]}](https://s0.wp.com/latex.php?latex=%7Bg%28x%29+%3D+%5Cfrac%7Bf%28x%29-f%280%29%7D%7Bx%7D%2C+x%5Cin%280%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is non-decreasing (strictly increasing).
is non-decreasing (strictly increasing). 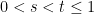
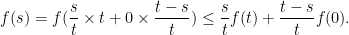
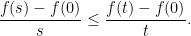
 by
by  .
.  where
where  is any connected set in
is any connected set in 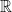 ,i.e., an interval which can be half open half closed or open or closed. The for any
,i.e., an interval which can be half open half closed or open or closed. The for any 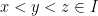 , we have
, we have
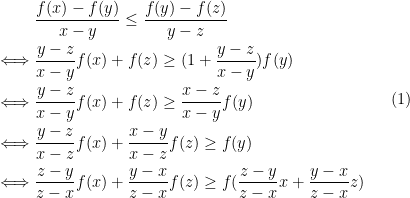
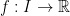 where
where ![{[a,b],(a,b),(a,b],[a,b)}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%2C%28a%2Cb%29%2C%28a%2Cb%5D%2C%5Ba%2Cb%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) where
where  . Then
. Then 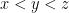 all in
all in 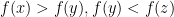
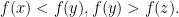
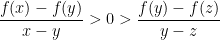
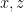 are interior point of
are interior point of ![{[x,z]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This means that
. This means that 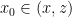 as
as 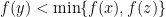 . Now for any
. Now for any 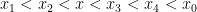 , by convexity and monotonicity of slope, we have
, by convexity and monotonicity of slope, we have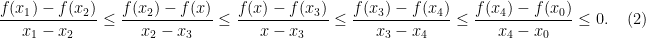
 . Thus
. Thus ![{I\cap (-\infty,x_0]}](https://s0.wp.com/latex.php?latex=%7BI%5Ccap+%28-%5Cinfty%2Cx_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Similarly, using monotonicity of slope, we have
. Similarly, using monotonicity of slope, we have  . Now if suppose either
. Now if suppose either  is the end point of
is the end point of  . Then there are only three possible cases
. Then there are only three possible cases
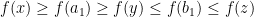

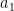 and
and 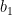 are interior point and we can proceed our previous argument and show
are interior point and we can proceed our previous argument and show 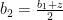 and ask the relation between
and ask the relation between 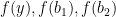 and
and  . The only non-ideal case is that
. The only non-ideal case is that  (the other case gives three interior point such that
(the other case gives three interior point such that  and we can employ our previous argument). We can then further have
and we can employ our previous argument). We can then further have  . Again there will be only one non-ideal case that
. Again there will be only one non-ideal case that  .
.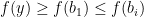 or the sequence
or the sequence  satisfies
satisfies  for all
for all  and
and 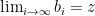 . If
. If 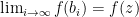 . But this is not possible because
. But this is not possible because 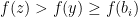 . Thus
. Thus  . Indeed, for any
. Indeed, for any 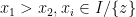 for
for  , there is a
, there is a 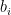 such that
such that 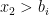 and so
and so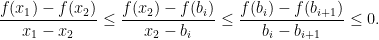
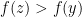 , we see
, we see ![{f:[a,b] \rightarrow \mathbb{R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5Ba%2Cb%5D+%5Crightarrow+%5Cmathbb%7BR%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is convex for some
is convex for some 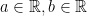 . Then
. Then 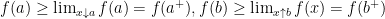 .
. 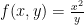 on
on 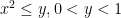 and the point
and the point 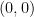 .
.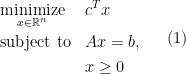
 and
and 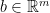 . The dual of the standard form is
. The dual of the standard form is 
 to Program
to Program 
 be the optimal value of Program
be the optimal value of Program  be an optimal solution to the same program. We would like to ask the following question:
be an optimal solution to the same program. We would like to ask the following question: 
 or even
or even 
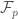 be
be  and the set of extreme rays be
and the set of extreme rays be  . Using our assumption A1, we know
. Using our assumption A1, we know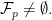




 is bounded, then we have
is bounded, then we have  where
where 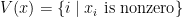 has all column independent. Here
has all column independent. Here  is the submatrix of
is the submatrix of  . By complementarity of LP
. By complementarity of LP 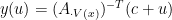
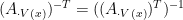 . What we have done is that under A1 and A2,
. What we have done is that under A1 and A2,
 .
.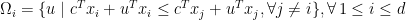
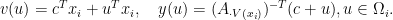

 here is arbitrary.
here is arbitrary.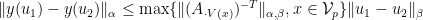
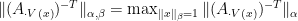 and
and  are arbitrary norms. We conclude the above discussion in the following theorem.
are arbitrary norms. We conclude the above discussion in the following theorem.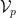 is the set of extreme points of the feasible region of
is the set of extreme points of the feasible region of 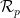 is the set of extreme points of the feasible region of
is the set of extreme points of the feasible region of  . Under assumption A1 and A2, we have for all
. Under assumption A1 and A2, we have for all  ,
,
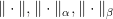 are arbitrary norms. Here
are arbitrary norms. Here  .
.
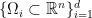 and a set of
and a set of  linear functions
linear functions 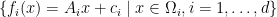 where each
where each 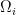 being closed polyhedrons in
being closed polyhedrons in 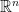 , i.e.,
, i.e.,  for some
for some 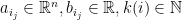 , and
, and 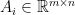 and
and 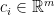 . Moreover, for any
. Moreover, for any  , and
, and 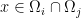 , we have
, we have  . Then we can define function
. Then we can define function  such that
such that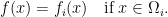
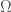 is convex. We now state a theorem concerning the Lipschitz constant of
is convex. We now state a theorem concerning the Lipschitz constant of  ,
, 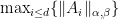 -Lipschitz continuous with respect to
-Lipschitz continuous with respect to  and
and  , i.e., for all
, i.e., for all  ,
, 
 is
is 
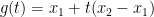 ,
,  and
and  . we see the inequality
. we see the inequality 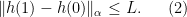
 for any
for any  , we have that there exists
, we have that there exists  and corresponding
and corresponding 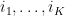 such that
such that 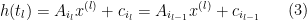
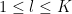 where
where 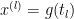 . We also let
. We also let 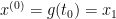 and
and 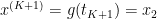 . These
. These 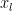 s have the property that
s have the property that 
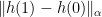 by
by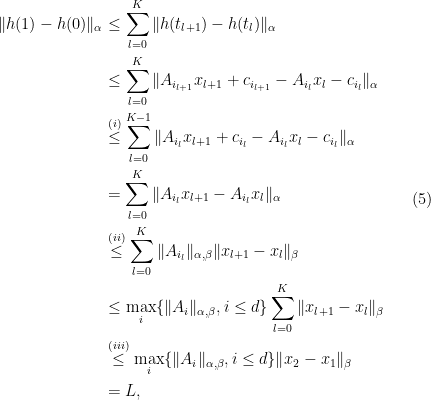
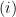 is due to inequality
is due to inequality  is due to the definition of operator norm and
is due to the definition of operator norm and  is using equality
is using equality 