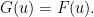Suppose you have a sequence of independent data 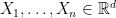 , how do you test that
, how do you test that  s all come from the same distribution, i.e., how do you test homogeneity of the data?
s all come from the same distribution, i.e., how do you test homogeneity of the data?
To make the problem more precise, suppose we have a distribution family indexed by  , i.e., a set
, i.e., a set
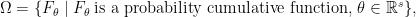
and each follows the distribution 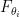 for some
for some 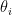 . Our problem is
. Our problem is
Is 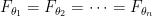 ?
?
If we have that  (known as the identifiability of
(known as the identifiability of  ), then our question becomes
), then our question becomes
Is 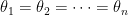 ?
?
Now suppose further that each 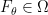 has a density
has a density  (so that we can write down the likelihood), the likelihood of seeing the independent sequence
(so that we can write down the likelihood), the likelihood of seeing the independent sequence  is
is
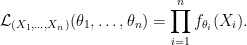
To test our question in a statistical way, we use hypothesis testing. Our null hypothesis is

and our alternative hypothesis is

Further denote the space of the null as 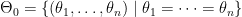 and the space of the alternative as
and the space of the alternative as 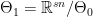 . A popular and natural approach is the likelihood ratio test. We construct the test statistic which is called likelihood ratio as
. A popular and natural approach is the likelihood ratio test. We construct the test statistic which is called likelihood ratio as
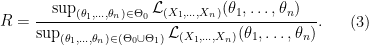
Intuitively, if our null hypothesis is indeed true, i.e., there is some 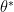 such that
such that  and follows
and follows 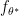 , then this ratio should be large and we have confidence that our null hypothesis is true. This means we should reject our null hypothesis if we find
, then this ratio should be large and we have confidence that our null hypothesis is true. This means we should reject our null hypothesis if we find  is small. Thus if we want to have a significance level
is small. Thus if we want to have a significance level  test of our null hypothesis, we should reject null hypothesis when
test of our null hypothesis, we should reject null hypothesis when  where
where  satisfies
satisfies
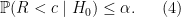
However, the main issue is that we don’t know the distribution of under  even if we know how to sample from each and the functional form of for each . The reason is that did not specify which (which equals to
even if we know how to sample from each and the functional form of for each . The reason is that did not specify which (which equals to 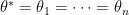 ) generates the data. So the distribution of may depend on as well and the real thing we need for is
) generates the data. So the distribution of may depend on as well and the real thing we need for is

Thus even if we want to know approximate the 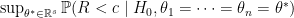 through computational methods, we have to simulate for each
through computational methods, we have to simulate for each 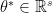 . As
. As  could be rather large (in fact as large as
could be rather large (in fact as large as  ), approximation can be time consuming as well.
), approximation can be time consuming as well.
Fortunately, if  is the so called location-scale family, we find that the distribution of is independent of and we are free to chose whichever we like. Let us define what is location-scale family, then state the theorem and prove it.
is the so called location-scale family, we find that the distribution of is independent of and we are free to chose whichever we like. Let us define what is location-scale family, then state the theorem and prove it.
Definition 1 Suppose we have a family of probability densities on 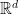 indexed by
indexed by 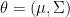 where
where  and
and  , the set of invertible matrices in
, the set of invertible matrices in  . The family is a local-scale family if there is a family member
. The family is a local-scale family if there is a family member  (called pivot) such that for any other with ,
(called pivot) such that for any other with ,
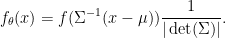
Thus if  follows , then
follows , then 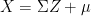 has probability density
has probability density  . Indeed, for any Borel set
. Indeed, for any Borel set 
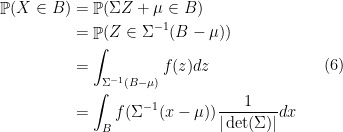
where we use a change of variable 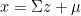 in the last equality and the last equality shows
in the last equality and the last equality shows  follows . We are now ready to state the theorem and prove it.
follows . We are now ready to state the theorem and prove it.
Theorem 2 Suppose our family of distribution is a local-scale family, then under the null hypothesis, there is a 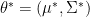 such that each follows
such that each follows 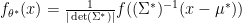 and the distribution of is independent of .
and the distribution of is independent of .
Since the distribution of is independent of under the null. This means that for any 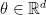 , and any
, and any

Thus we can choose any family member of to sample and approximates the distribution of using empirical distribution as long as is a location-scale family!
Proof: We need to show that the ratio has distribution independent of . Since 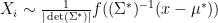 and is a location scale family, we can assume they are generated via
and is a location scale family, we can assume they are generated via  where follows a pivot and
where follows a pivot and 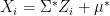 . Then the likelihood of
. Then the likelihood of 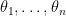 is
is
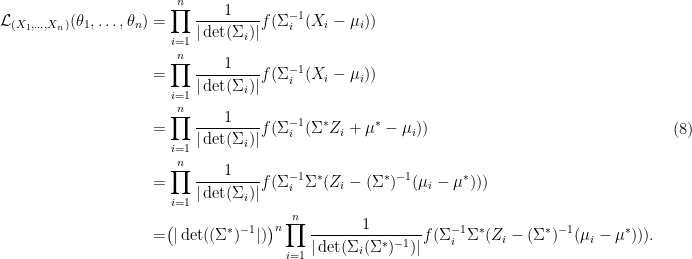
Thus the likelihood ratio reduces to

Now let’s define  ,
,  ,
,  and
and 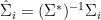 . Note that since
. Note that since 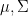 ,
,  can vary all over the space
can vary all over the space 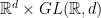 , so is
, so is 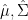 ,
, 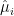 and
and 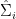 . The equality (10) can be rewritten as
. The equality (10) can be rewritten as

As we just argued, , and can vary all over the space without any restriction, the supremum in the numerator and denominator thus does not depend on the choice 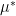 and
and 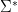 at all. So our theorem is proved.
at all. So our theorem is proved. 
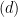



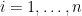

![\displaystyle \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right]. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
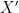

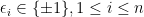
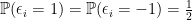
![\displaystyle \begin{aligned} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n f(X_i)- \mathbb{E}f(X_i) \right) \right] \\ \overset{(a)}{=} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n f(X_i)- \mathbb{E}_{X_i'}f(X_i') \right) \right] \\ \overset{(b)}{ =} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n \mathbb{E}_{X_i'}(f(X_i)-f(X_i')) \right) \right]\\ \overset{(c)}{\leq} & \mathbb{E}_{X,X'}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n (f(X_i)-f(X_i')) \right) \right]\\ \overset{(d)}{=} & \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n \epsilon_i(f(X_i)-f(X_i')) \right) \right]\\ \overset{(e)}{=} & \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]+ \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i') \right| \right]\\ \overset{(f)}{=} & 2 \mathbb{E}_{X,\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]. \end{aligned} \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+f%28X_i%29-+%5Cmathbb%7BE%7Df%28X_i%29+%5Cright%29+%5Cright%5D+%5C%5C+%5Coverset%7B%28a%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+f%28X_i%29-+%5Cmathbb%7BE%7D_%7BX_i%27%7Df%28X_i%27%29+%5Cright%29+%5Cright%5D+%5C%5C+%5Coverset%7B%28b%29%7D%7B+%3D%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb%7BE%7D_%7BX_i%27%7D%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28c%29%7D%7B%5Cleq%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28d%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28e%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D%2B+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%27%29+%5Cright%7C+%5Cright%5D%5C%5C+%5Coverset%7B%28f%29%7D%7B%3D%7D+%26+2+%5Cmathbb%7BE%7D_%7BX%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{ \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]}](https://s0.wp.com/latex.php?latex=%7B+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


![{\mathbb{E}_{X'}[\cdot]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7BX%27%7D%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathbb{E}[ \cdot \mid X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B+%5Ccdot+%5Cmid+X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
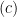
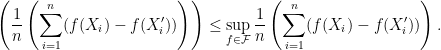
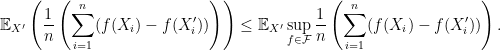

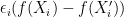
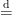


![\displaystyle [f_j(X_i)-f_j(X_i')]_{1\leq i\leq n,1\leq j\leq m} \overset{\text{d}}{=} \left[\epsilon_i \left(f_j(X_i)-f_j(X_i')\right)\right]_{1\leq i\leq n,1\leq j\leq m}. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+i%5Cleq+n%2C1%5Cleq+j%5Cleq+m%7D+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5Cleft%5B%5Cepsilon_i+%5Cleft%28f_j%28X_i%29-f_j%28X_i%27%29%5Cright%29%5Cright%5D_%7B1%5Cleq+i%5Cleq+n%2C1%5Cleq+j%5Cleq+m%7D.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)

![\displaystyle [f_j(X_i) - f_j(X_i')]_{j=1}^m \overset{\text{d}}{=} [\epsilon_i (f_j(X_i) - f_j(X_i'))]_{j=1}^m,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bf_j%28X_i%29+-+f_j%28X_i%27%29%5D_%7Bj%3D1%7D%5Em+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5B%5Cepsilon_i+%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![[\epsilon_i (f_j(X_i) - f_j(X_i'))]_{j=1}^m = \epsilon_i [(f_j(X_i) - f_j(X_i'))]_{j=1}^m.](https://s0.wp.com/latex.php?latex=%5B%5Cepsilon_i+%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em+%3D+%5Cepsilon_i+%5B%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em.+&bg=ffffff&fg=000000&s=0&c=20201002)
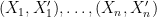
![\displaystyle [[f_j(X_i)-f_j(X_i')]_{1\leq j\leq m}]_{1\leq i\leq n} \overset{\text{d}}{=} [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)



![\displaystyle \begin{aligned} &\mathbb{P}( [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B)\\ \overset{(a)}{=}& \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B | \epsilon = \bar{\epsilon})\\ \overset{(b)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\bar{\epsilon}_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B | \epsilon = \bar{\epsilon})\\ \overset{(c)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\bar{\epsilon}_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B )\\ \overset{(d)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B )\\ =& \mathbb{P}( [[(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B ). \end{aligned} \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26%5Cmathbb%7BP%7D%28+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B%29%5C%5C+%5Coverset%7B%28a%29%7D%7B%3D%7D%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%7C+%5Cepsilon+%3D+%5Cbar%7B%5Cepsilon%7D%29%5C%5C+%5Coverset%7B%28b%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cbar%7B%5Cepsilon%7D_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%7C+%5Cepsilon+%3D+%5Cbar%7B%5Cepsilon%7D%29%5C%5C+%5Coverset%7B%28c%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cbar%7B%5Cepsilon%7D_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29%5C%5C+%5Coverset%7B%28d%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29%5C%5C+%3D%26+%5Cmathbb%7BP%7D%28+%5B%5B%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)

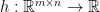
![\displaystyle \mathbb{E}\left[h\left([f_j(X_i)-f_j(X_i')]_{1\leq j\leq m, \;1\leq i\leq n} \right)\right] = \mathbb{E}\left[h\left(\left[\epsilon_i(f_j(X_i)-f_j(X_i'))\right]_{1\leq j\leq m, \;1\leq i\leq n} \right)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft%5Bh%5Cleft%28%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+j%5Cleq+m%2C+%5C%3B1%5Cleq+i%5Cleq+n%7D+%5Cright%29%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5Bh%5Cleft%28%5Cleft%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5Cright%5D_%7B1%5Cleq+j%5Cleq+m%2C+%5C%3B1%5Cleq+i%5Cleq+n%7D+%5Cright%29%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002)

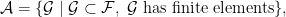
![\displaystyle \begin{aligned} \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right] := \sup_{\mathcal{G}\in \mathcal{A}} \mathbb{E}\left [ \sup_{f\in \mathcal{G}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right]. \end{aligned} \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D+%3A%3D+%5Csup_%7B%5Cmathcal%7BG%7D%5Cin+%5Cmathcal%7BA%7D%7D+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BG%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
 on real line
on real line 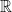 and
and 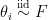 where
where  and
and 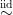 means “independently and identically distributed as”. We denote
means “independently and identically distributed as”. We denote 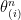 to be the
to be the  -th largest random variable of the
-th largest random variable of the 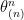 is the largest value and
is the largest value and  is the smallest of the
is the smallest of the  does not mean taking to the
does not mean taking to the  are called order statistics in Statistics. They are
are called order statistics in Statistics. They are  ,
,  and
and  , we have
, we have 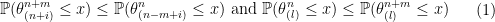

 -th largest value. The left inequalities of the inequality
-th largest value. The left inequalities of the inequality  -th order statistic is in expectation.
-th order statistic is in expectation.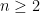 and take
and take 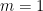 ,
,  , and
, and  in Theorem
in Theorem 
 , then we can take
, then we can take  ,
,  . Then equation
. Then equation 
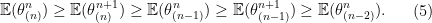
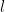 and
and 
 and
and  are interlacing. The main idea of the proof is putting
are interlacing. The main idea of the proof is putting 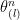 and
and  and
and  in the same probability space and arguing that we actually have almost sure inequality instead of just expectation or stochastically dominance. This technique is known as coupling.
in the same probability space and arguing that we actually have almost sure inequality instead of just expectation or stochastically dominance. This technique is known as coupling.  follows
follows 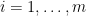 . We now consider all the
. We now consider all the 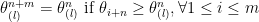

 -th largest value
-th largest value  is always smaller than the
is always smaller than the 

 have joint distribution
have joint distribution  . Denote
. Denote  to be the order statistics. Now consider only the first
to be the order statistics. Now consider only the first 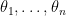 . Denote their marginal distribution as
. Denote their marginal distribution as 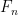 . We denote the order statistics of these
. We denote the order statistics of these  . Then for any
. Then for any  and
and 
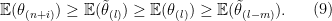
 and order them so that we have
and order them so that we have  s. Now if we generate the extra
s. Now if we generate the extra  and the first
and the first 
 is at most
is at most 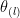 since we have
since we have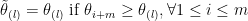

 s, the
s, the  is always smaller than the
is always smaller than the 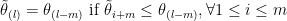

 for any
for any 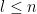 .
.  with parameter (index)
with parameter (index)  is said to be a natural exponential family if
is said to be a natural exponential family if 
 , we call
, we call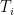 : natural sufficient statistic
: natural sufficient statistic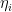 : natural parameter
: natural parameter : natural parameter space.
: natural parameter space.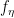 ,
, 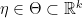 , and a random variable
, and a random variable  , a statistic
, a statistic 
 is independent of
is independent of  . A sufficient statistic
. A sufficient statistic  , there is a function
, there is a function  such that
such that  .
. is
is .
.
 .
.
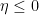 for the integral
for the integral  to be finite and
to be finite and  for the integral
for the integral  to be finite. This means actually
to be finite. This means actually  and so the natural parameter space is a single point
and so the natural parameter space is a single point  .
. is indeed sufficient. But any constant estimator is also sufficient and minimal as any other sufficient statistic under a constant function is a constant. But
is indeed sufficient. But any constant estimator is also sufficient and minimal as any other sufficient statistic under a constant function is a constant. But  ,
, 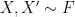 ,
,  where
where  are cumulative distribution function and
are cumulative distribution function and  are finite. We prove the following theorem.
are finite. We prove the following theorem. norm) For independent random variables
norm) For independent random variables 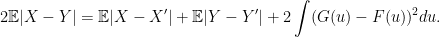

 .
. is usually referred as mean absolute difference and it measures the spread of a distribution. I don’t know the term for the quantity
is usually referred as mean absolute difference and it measures the spread of a distribution. I don’t know the term for the quantity  but what it measures is the difference between the distribution
but what it measures is the difference between the distribution  , then the expected error (the cross mean difference) in terms of absolute value (
, then the expected error (the cross mean difference) in terms of absolute value ( , which can be considered as variance and the difference in the two distribution ,i.e.,
, which can be considered as variance and the difference in the two distribution ,i.e.,  , which can be considered as bias.
, which can be considered as bias. norm) and it is
norm) and it is
 , and the difference of mean can be considered as bias as well.
, and the difference of mean can be considered as bias as well. both have first finite moments. In the case either
both have first finite moments. In the case either 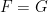 .
.

 and
and 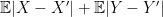 which is finite because
which is finite because  is
is 
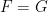 . If
. If 

 ,
,