Suppose we have a random vector 
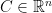
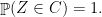
If you are doing things with convexity, then you may wonder whether

This is certainly true if 
Theorem 1 For any convex set
, and for any random vector
its expectation is still in
as long as the mean exists.
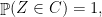

Skip the following remark if you don’t know or not familiar with measure theory.
Remark 1 If you are a measure theoretic person, you might wonder whether
and
where
is the borel sigma-algebra. Then we can either add the condition that the event
or
is understood as
is a measurable event with respect to the completed measure space
and we overload the notation
to mean
. The probability space
To have some preparation for the proof, recall the separating hyperplane theorem of convex set.
Theorem 2 (Separating Hyperplane theorem) Suppose
are convex sets in
and
, then there exists a nonzero
such that
for all
.
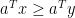
Also recall the following little facts about convexity.
- Any convex set in
is always an interval.
- Any affine space of
dimension in
for some
and
.
We are now ready to prove Theorem 1.
Proof of Theorem 1: We may suppose that 

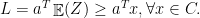
Since 
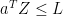
almost surely. Since 




Repeat the above argument, we can decrease the dimension until 
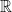
This is almost trivial. Suppose the interval is bounded. If the interval is closed, then since taking expectation preserves order, i.e., 
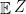


 is a random transformation from a probability space
is a random transformation from a probability space  to a measurable space
to a measurable space  where each singleton set of
where each singleton set of  is in
is in 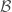 . Let each
. Let each  be a real valued (Borel measurable) function with its domain to be
be a real valued (Borel measurable) function with its domain to be  ,
, 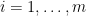 . Given
. Given
 such that
such that  takes no more than
takes no more than 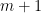 values in
values in 
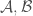 , then just ignore these. I put these term here just to make sure the that the theorem is rigorous enough.)
, then just ignore these. I put these term here just to make sure the that the theorem is rigorous enough.) many expectations, no matter what kind of source the randomness comes from, i.e., what
many expectations, no matter what kind of source the randomness comes from, i.e., what  with its first
with its first 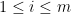


 and
and  .
. and its all
and its all  th order moments are finite, i.e.,
th order moments are finite, i.e.,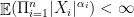
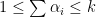 . Each
. Each 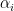 here is a nonnegative integer. The total number of moments in this case is
here is a nonnegative integer. The total number of moments in this case is  . Then there is a real random vector
. Then there is a real random vector  such that it takes no more than
such that it takes no more than  values, and
values, and
 , and any random variable
, and any random variable 

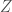 takes only finitely many value. But it is true that
takes only finitely many value. But it is true that 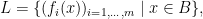
 is
is
 which takes value only in
which takes value only in  , by Lemma
, by Lemma 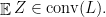
 has a FINITE representation in terms of
has a FINITE representation in terms of 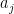 s!
s!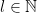 ,
, 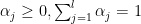 and
and  such that
such that
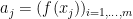 for some
for some 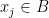 , we can simply take the distribution of
, we can simply take the distribution of 
 .
. 