In this post, we study a few probability one results conerning the rank of random matrices: with probability one,
- a random asymmetric matrix has full rank;
- a random symmetric matrix has full rank;
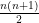 many random rank one positive semidefinite matrices (belonging to
many random rank one positive semidefinite matrices (belonging to  ) are linearly independent.
) are linearly independent.
At least for the first two, they look quite natural and should be correct at first glance. However, to rigorously prove them does require some effort. The post is trying to show that one can use the concept of independence to prove the above assertions. Indeed, all the proof follows an inductive argument where independence makes life much easier:
- Draw the first sample, it satisfies the property we want to show,
- Suppose first
 samples satisfy the property we want to show, draw the next sample. Since it is independent of the previous samples, the first samples can be considered as fixed. Then we make some effort to say the first
samples satisfy the property we want to show, draw the next sample. Since it is independent of the previous samples, the first samples can be considered as fixed. Then we make some effort to say the first  sample does satisfy the property.
sample does satisfy the property.
Before we going into each example, we further note for any probability measure that is absolutely continuous respect to the measure introduced below and vice versa (so independence is not needed), the probability  results listed above still hold.
results listed above still hold.
1. Random Matrices are full rank
Suppose 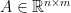 with
with ![{A=[a_{ij}]}](https://s0.wp.com/latex.php?latex=%7BA%3D%5Ba_%7Bij%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and each entry of
and each entry of  is drawn independently from standard Gaussian
is drawn independently from standard Gaussian 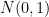 . We prove that
. We prove that  has rank
has rank  with probability .
with probability .
To start, we should assume without loss of generality that  . Otherwise, we just repeat the following argument for
. Otherwise, we just repeat the following argument for  .
.
The trick is to use the independence structure and consider columns of are drawn from left to right. Let’s write the  -th column of by
-th column of by 
For the first column, we know  is linearly independent because it is
is linearly independent because it is  with probability . For the second column, because it is drawn independently from the first column, we can consider the first column is fixed, and the probability of
with probability . For the second column, because it is drawn independently from the first column, we can consider the first column is fixed, and the probability of  fall in to the span of a fixed column is because has a continuous density in
fall in to the span of a fixed column is because has a continuous density in 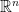 . Thus the first two columns are linearly independent.
. Thus the first two columns are linearly independent.
For general 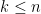 , because , we know the first
, because , we know the first 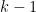 columns forms a subspace in and so
columns forms a subspace in and so 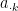 falls into that subspace with probability (linear subspace has Lebesgue measure in and Gaussian measure is absolutely continuous with respect to Lebesgue measure and vice versa). Thus we see first columns are linearly independent. Proceeding the argument until
falls into that subspace with probability (linear subspace has Lebesgue measure in and Gaussian measure is absolutely continuous with respect to Lebesgue measure and vice versa). Thus we see first columns are linearly independent. Proceeding the argument until 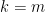 completes the proof.
completes the proof.
2. Symmetric Matrices are full rank
Suppose 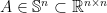 with and each entry of the upper half of ,
with and each entry of the upper half of , 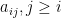 , is drawn independently from standard Gaussian . We prove that has rank
, is drawn independently from standard Gaussian . We prove that has rank  .
.
Let’s write the -th row of by 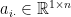 . For the first entries of the -th row, we write
. For the first entries of the -th row, we write 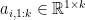 . Similarly,
. Similarly,  denotes the first entries of the -th column. For the top left
denotes the first entries of the -th column. For the top left  submatrix of , we denote it by
submatrix of , we denote it by  . Similar notation applies to other submatrices.
. Similar notation applies to other submatrices.
The idea is drawing each column of from left to right sequentially and using the independence structure. Starting from the first column, with probability one, we have that is linearly independent (meaning  ).
).
Now since is drawn and the second column except the first entry is independent of , we know it is in the span of if the second column is  (
(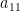 is with probability 0) multiple of . This still happens with probability since each entry of
is with probability 0) multiple of . This still happens with probability since each entry of  has continuous probability density and is drawn independently from .
has continuous probability density and is drawn independently from .
Now assume we have drawn the first columns of , the first columns are linearly independent with probability , and the left top submatrix of is invertible (the base case is what we just proved). We want to show after we draw the column, the first columns are still linearly independent with probability . Since the first columns is drawn, the first entries of the column  is fixed, we wish to show the rest
is fixed, we wish to show the rest 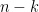 entries which are drawn independently from all previous columns will ensure linearly independence of first columns.
entries which are drawn independently from all previous columns will ensure linearly independence of first columns.
Suppose instead is linearly dependent with first columns of . Since the left top submatrix of is invertible, we know there is only one way to write as a linear combination of previous columns. More precisely, we have

This means has to be a fixed vector which happens with probability because the last entries of is drawn independently from , 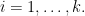 Note this implies that the first columns of are linearly independent as well as the left top
Note this implies that the first columns of are linearly independent as well as the left top  submatrix of is invertible because we can repeat the argument simply by thinking is (instead of
submatrix of is invertible because we can repeat the argument simply by thinking is (instead of 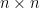 ). Thus the induction is complete and we prove indeed has rank with probability .
). Thus the induction is complete and we prove indeed has rank with probability .
3. Rank positive semidefinite matrices are linearly independent
This time, we consider 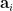 ,
,  are drawn independently from standard normal distribution in . Denote the set of symmetric matrices in as
are drawn independently from standard normal distribution in . Denote the set of symmetric matrices in as 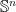 . We show that with probability the matrices
. We show that with probability the matrices

are linearly independent in .
Denote the standard -th basis vector in as 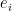 . First, let us consider the following basis (which can be verified easily) in ,
. First, let us consider the following basis (which can be verified easily) in ,

We order the basis according to the lexicographical order on 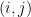 . Suppose
. Suppose 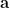 follows standard normal distribution in , we prove that for any fixed linear subspace
follows standard normal distribution in , we prove that for any fixed linear subspace  with dimension less than , we have
with dimension less than , we have

We start by applying an fixed invertible linear map  to
to  so that the basis of
so that the basis of 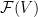 is the first
is the first  many basis vector of
many basis vector of 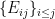 ({in lexicographical order.}), and the basis of the orthogonal complement (defined via the trace inner product) of ,
({in lexicographical order.}), and the basis of the orthogonal complement (defined via the trace inner product) of ,  , is mapped to the rest of the basis vector of under
, is mapped to the rest of the basis vector of under  . We then only need to prove
. We then only need to prove

We prove by contradiction. Suppose  . It implies that there exists infinitely many
. It implies that there exists infinitely many 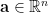 such that
such that 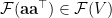 . Moreover, each component of takes infinitely many values. We show such situation cannot occur. Denote the
. Moreover, each component of takes infinitely many values. We show such situation cannot occur. Denote the  -th largest element in
-th largest element in 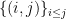 as
as  . Since has dimension less than ,
. Since has dimension less than ,  contains nonzero element and so
contains nonzero element and so
![\displaystyle \mathcal{F}(\mathbf{a}\mathbf{a}^\top) \in \mathcal{F}(V) \iff [\mathcal{F}(\mathbf{a}\mathbf{a}^\top)]_{ij}=0,\quad \forall (i,j) > (i_0,j_0) \,\text{in lexicographical order.}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathcal%7BF%7D%28%5Cmathbf%7Ba%7D%5Cmathbf%7Ba%7D%5E%5Ctop%29+%5Cin+%5Cmathcal%7BF%7D%28V%29+%5Ciff+%5B%5Cmathcal%7BF%7D%28%5Cmathbf%7Ba%7D%5Cmathbf%7Ba%7D%5E%5Ctop%29%5D_%7Bij%7D%3D0%2C%5Cquad+%5Cforall+%28i%2Cj%29+%3E+%28i_0%2Cj_0%29+%5C%2C%5Ctext%7Bin+lexicographical+order.%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Now fix an  , we know
, we know ![{ [\mathcal{F}(\mathbf{a}\mathbf{a}^\top)]_{i_1j_1}=0}](https://s0.wp.com/latex.php?latex=%7B+%5B%5Cmathcal%7BF%7D%28%5Cmathbf%7Ba%7D%5Cmathbf%7Ba%7D%5E%5Ctop%29%5D_%7Bi_1j_1%7D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) means that there is some
means that there is some 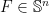 (depending only on ) such that
(depending only on ) such that

where  is the -th complement of . Now if we fix
is the -th complement of . Now if we fix 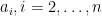 and only vary
and only vary 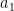 , then we have
, then we have

which holds for infinitely many 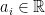 only if
only if
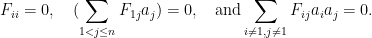
Thus we can repeat the argument as before and conclude that 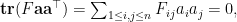 holds for infinitely many with each component taking infinitely many values only if
holds for infinitely many with each component taking infinitely many values only if  . This contradicts the fact that is invertible and hence we must have
. This contradicts the fact that is invertible and hence we must have
Now proving 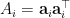 spans with probability is easy. Because for each , the
spans with probability is easy. Because for each , the 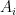 with
with  being drawn can be considered fixed because
being drawn can be considered fixed because  is drawn independently of . But the probability of stays in the span of
is drawn independently of . But the probability of stays in the span of  is by previous result and hence is linearly independent of all . This argument continues to hold for
is by previous result and hence is linearly independent of all . This argument continues to hold for  because the space spanned by
because the space spanned by 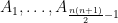 is at most
is at most 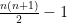 and so previous result applies. This completes the proof.
and so previous result applies. This completes the proof.
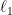

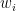


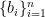
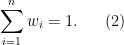
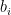
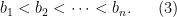




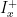


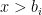
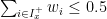

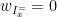


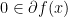


![\displaystyle \partial f(x) = - \sum_{i\in I^-_x} w_i + \sum_{i\in I^+_x} w_i + w_{I_x^=} \times [-1,1], \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpartial+f%28x%29+%3D+-+%5Csum_%7Bi%5Cin+I%5E-_x%7D+w_i+%2B+%5Csum_%7Bi%5Cin+I%5E%2B_x%7D+w_i+%2B+w_%7BI_x%5E%3D%7D+%5Ctimes+%5B-1%2C1%5D%2C+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{w_{I_x^=} \times [-1,1] = [-w_{I_x^=}, w_{I_x^=}]}](https://s0.wp.com/latex.php?latex=%7Bw_%7BI_x%5E%3D%7D+%5Ctimes+%5B-1%2C1%5D+%3D+%5B-w_%7BI_x%5E%3D%7D%2C+w_%7BI_x%5E%3D%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{w_{I_x^=} \times [-1,1] = 0}](https://s0.wp.com/latex.php?latex=%7Bw_%7BI_x%5E%3D%7D+%5Ctimes+%5B-1%2C1%5D+%3D+0%7D&bg=ffffff&fg=000000&s=0&c=20201002)
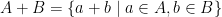
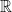
![\displaystyle 0 \in \partial f(x) = - \sum_{i\in I^-_x} w_i + \sum_{i\in I^+_x} w_i + w_{I_x^=} \times [-1,1]. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+0+%5Cin+%5Cpartial+f%28x%29+%3D+-+%5Csum_%7Bi%5Cin+I%5E-_x%7D+w_i+%2B+%5Csum_%7Bi%5Cin+I%5E%2B_x%7D+w_i+%2B+w_%7BI_x%5E%3D%7D+%5Ctimes+%5B-1%2C1%5D.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)



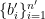
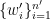

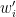


 and
and  . The dual program is accordingly
. The dual program is accordingly 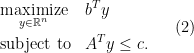
 that are feasible for
that are feasible for 
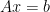 , hence the above condition is equivalent to
, hence the above condition is equivalent to
 , and using the feasibility
, and using the feasibility 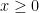 and
and 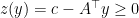 , we conclude
, we conclude ![\displaystyle \textbf{complementarity:} \quad x_i [z(y) ]_i= 0 \quad \text{for all}\;1\leq i\leq n. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctextbf%7Bcomplementarity%3A%7D+%5Cquad+x_i+%5Bz%28y%29+%5D_i%3D+0+%5Cquad+%5Ctext%7Bfor+all%7D%5C%3B1%5Cleq+i%5Cleq+n.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
 and
and ![{[z(y)]_i}](https://s0.wp.com/latex.php?latex=%7B%5Bz%28y%29%5D_i%7D&bg=ffffff&fg=000000&s=0&c=20201002) are
are  respectively. The above derivation shows that strong duality
respectively. The above derivation shows that strong duality  .
.![\displaystyle \textbf{strict complementarity:} \quad \text{for all}\; i \quad x_i = 0 \iff [z(y^*)]_i > 0. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Ctextbf%7Bstrict+complementarity%3A%7D+%5Cquad+%5Ctext%7Bfor+all%7D%5C%3B+i+%5Cquad+x_i+%3D+0+%5Ciff+%09%5Bz%28y%5E%2A%29%5D_i+%3E+0.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
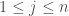 , there either exists a primal optimal
, there either exists a primal optimal  or there exists a dual optimal
or there exists a dual optimal 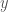 such that
such that ![{[z(y)]_j >0}](https://s0.wp.com/latex.php?latex=%7B%5Bz%28y%29%5D_j+%3E0%7D&bg=ffffff&fg=444444&s=0&c=20201002) .
.  , either there is an optimal
, either there is an optimal 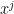 such that
such that 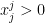 or there is an optimal
or there is an optimal  such that
such that ![{[z(y^j)]_j >0}](https://s0.wp.com/latex.php?latex=%7B%5Bz%28y%5Ej%29%5D_j+%3E0%7D&bg=ffffff&fg=000000&s=0&c=20201002) but not both due to
but not both due to  be the subset of
be the subset of 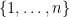 consists of
consists of  such that
such that  . Consequently, using Lemma
. Consequently, using Lemma 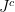 consists of indices s.t. an optimal
consists of indices s.t. an optimal ![{[z(y^j)]_j>0}](https://s0.wp.com/latex.php?latex=%7B%5Bz%28y%5Ej%29%5D_j%3E0%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then the desired
. Then the desired 
 is the cardinality of
is the cardinality of  . Fix an index
. Fix an index 
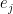 is the
is the 
 such that
such that
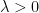 , then
, then  is optimal for
is optimal for ![\displaystyle c - A^\top\left( \frac{y}{\lambda} \right)\geq \frac{1}{\lambda }e_j \implies [z(\frac{y}{\lambda})]_j >0. \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09c+-+A%5E%5Ctop%5Cleft%28+%5Cfrac%7By%7D%7B%5Clambda%7D+%5Cright%29%5Cgeq+%5Cfrac%7B1%7D%7B%5Clambda+%7De_j+%5Cimplies+%5Bz%28%5Cfrac%7By%7D%7B%5Clambda%7D%29%5D_j+%3E0.+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
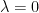 . Then
. Then 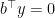 and
and  . Now take any
. Now take any 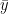 that is optimal for
that is optimal for  satisfies the conclusion in Lemma
satisfies the conclusion in Lemma ![{[z(y)]_j>0}](https://s0.wp.com/latex.php?latex=%7B%5Bz%28y%29%5D_j%3E0%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Suppose we are now in the second situation. Then this directly means that there is a feasible
. Suppose we are now in the second situation. Then this directly means that there is a feasible  .
.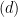 below), when I tried to use it in my own research.
below), when I tried to use it in my own research. ,
,  where
where  is a set. We are given a series of independent random varaibles
is a set. We are given a series of independent random varaibles  ,
, 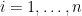 , which take value in
, which take value in  . A typical quantity appeared in empirical process theory is
. A typical quantity appeared in empirical process theory is![\displaystyle \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right]. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
 , denoted as
, denoted as 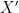 , and (2)
, and (2) 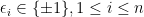 with
with 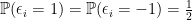 . Denote
. Denote 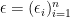 . Let us display the symmetrization argument:
. Let us display the symmetrization argument:![\displaystyle \begin{aligned} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n f(X_i)- \mathbb{E}f(X_i) \right) \right] \\ \overset{(a)}{=} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n f(X_i)- \mathbb{E}_{X_i'}f(X_i') \right) \right] \\ \overset{(b)}{ =} & \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n \mathbb{E}_{X_i'}(f(X_i)-f(X_i')) \right) \right]\\ \overset{(c)}{\leq} & \mathbb{E}_{X,X'}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n (f(X_i)-f(X_i')) \right) \right]\\ \overset{(d)}{=} & \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left( \sum_{i=1}^n \epsilon_i(f(X_i)-f(X_i')) \right) \right]\\ \overset{(e)}{=} & \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]+ \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i') \right| \right]\\ \overset{(f)}{=} & 2 \mathbb{E}_{X,\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]. \end{aligned} \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+f%28X_i%29-+%5Cmathbb%7BE%7Df%28X_i%29+%5Cright%29+%5Cright%5D+%5C%5C+%5Coverset%7B%28a%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+f%28X_i%29-+%5Cmathbb%7BE%7D_%7BX_i%27%7Df%28X_i%27%29+%5Cright%29+%5Cright%5D+%5C%5C+%5Coverset%7B%28b%29%7D%7B+%3D%7D+%26+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%5Cmathbb%7BE%7D_%7BX_i%27%7D%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28c%29%7D%7B%5Cleq%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28d%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%28+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_i%28f%28X_i%29-f%28X_i%27%29%29+%5Cright%29+%5Cright%5D%5C%5C+%5Coverset%7B%28e%29%7D%7B%3D%7D+%26+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D%2B+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%27%29+%5Cright%7C+%5Cright%5D%5C%5C+%5Coverset%7B%28f%29%7D%7B%3D%7D+%26+2+%5Cmathbb%7BE%7D_%7BX%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![{ \mathbb{E}_{X,X',\epsilon}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\left| \sum_{i=1}^n \epsilon_if(X_i) \right| \right]}](https://s0.wp.com/latex.php?latex=%7B+%5Cmathbb%7BE%7D_%7BX%2CX%27%2C%5Cepsilon%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Cleft%7C+%5Csum_%7Bi%3D1%7D%5En+%5Cepsilon_if%28X_i%29+%5Cright%7C+%5Cright%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is called the Rademacher complexity of
is called the Rademacher complexity of 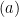 and
and  , we uses the fact that
, we uses the fact that 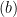 , we use the fact that
, we use the fact that ![{\mathbb{E}_{X'}[\cdot]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D_%7BX%27%7D%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as ![{\mathbb{E}[ \cdot \mid X]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B+%5Ccdot+%5Cmid+X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ). In step
). In step 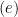 , we use the triangle inequality. Next, we explain the steps
, we use the triangle inequality. Next, we explain the steps 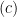 and
and 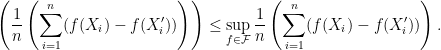
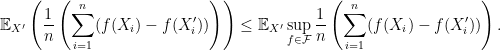
 has the same distribution as
has the same distribution as 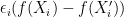 . I was not convinced by this argument since we are taking a superium over
. I was not convinced by this argument since we are taking a superium over 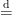 . The things we are (or I am) missing is that there are
. The things we are (or I am) missing is that there are 
 is fixed. What we really need is to ensure that for any fixed
is fixed. What we really need is to ensure that for any fixed ![\displaystyle [f_j(X_i)-f_j(X_i')]_{1\leq i\leq n,1\leq j\leq m} \overset{\text{d}}{=} \left[\epsilon_i \left(f_j(X_i)-f_j(X_i')\right)\right]_{1\leq i\leq n,1\leq j\leq m}. \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+i%5Cleq+n%2C1%5Cleq+j%5Cleq+m%7D+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5Cleft%5B%5Cepsilon_i+%5Cleft%28f_j%28X_i%29-f_j%28X_i%27%29%5Cright%29%5Cright%5D_%7B1%5Cleq+i%5Cleq+n%2C1%5Cleq+j%5Cleq+m%7D.+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle [f_j(X_i) - f_j(X_i')]_{j=1}^m \overset{\text{d}}{=} [\epsilon_i (f_j(X_i) - f_j(X_i'))]_{j=1}^m,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Bf_j%28X_i%29+-+f_j%28X_i%27%29%5D_%7Bj%3D1%7D%5Em+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5B%5Cepsilon_i+%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
![[\epsilon_i (f_j(X_i) - f_j(X_i'))]_{j=1}^m = \epsilon_i [(f_j(X_i) - f_j(X_i'))]_{j=1}^m.](https://s0.wp.com/latex.php?latex=%5B%5Cepsilon_i+%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em+%3D+%5Cepsilon_i+%5B%28f_j%28X_i%29+-+f_j%28X_i%27%29%29%5D_%7Bj%3D1%7D%5Em.+&bg=ffffff&fg=000000&s=0&c=20201002) Hence, because of independence of
Hence, because of independence of 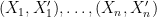 , we know that
, we know that![\displaystyle [[f_j(X_i)-f_j(X_i')]_{1\leq j\leq m}]_{1\leq i\leq n} \overset{\text{d}}{=} [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5B%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Coverset%7B%5Ctext%7Bd%7D%7D%7B%3D%7D+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D.+&bg=ffffff&fg=000000&s=0&c=20201002)
 . If
. If  uniformly, then we see
uniformly, then we see 
![\displaystyle \begin{aligned} &\mathbb{P}( [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B)\\ \overset{(a)}{=}& \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\epsilon_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B | \epsilon = \bar{\epsilon})\\ \overset{(b)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\bar{\epsilon}_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B | \epsilon = \bar{\epsilon})\\ \overset{(c)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[\bar{\epsilon}_i(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B )\\ \overset{(d)}{=} & \sum_{\bar{\epsilon} \in \{\pm 1\}^n}\frac{1}{2^n} \mathbb{P}( [[(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B )\\ =& \mathbb{P}( [[(f_j(X_i)-f_j(X_i'))]_{1\leq j\leq m}]_{1\leq i\leq n} \in B ). \end{aligned} \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%26%5Cmathbb%7BP%7D%28+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B%29%5C%5C+%5Coverset%7B%28a%29%7D%7B%3D%7D%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%7C+%5Cepsilon+%3D+%5Cbar%7B%5Cepsilon%7D%29%5C%5C+%5Coverset%7B%28b%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cbar%7B%5Cepsilon%7D_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%7C+%5Cepsilon+%3D+%5Cbar%7B%5Cepsilon%7D%29%5C%5C+%5Coverset%7B%28c%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%5Cbar%7B%5Cepsilon%7D_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29%5C%5C+%5Coverset%7B%28d%29%7D%7B%3D%7D+%26+%5Csum_%7B%5Cbar%7B%5Cepsilon%7D+%5Cin+%5C%7B%5Cpm+1%5C%7D%5En%7D%5Cfrac%7B1%7D%7B2%5En%7D+%5Cmathbb%7BP%7D%28+%5B%5B%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29%5C%5C+%3D%26+%5Cmathbb%7BP%7D%28+%5B%5B%28f_j%28X_i%29-f_j%28X_i%27%29%29%5D_%7B1%5Cleq+j%5Cleq+m%7D%5D_%7B1%5Cleq+i%5Cleq+n%7D+%5Cin+B+%29.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
 since this is the condition in the conditional probability. In
since this is the condition in the conditional probability. In 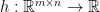 ,
,![\displaystyle \mathbb{E}\left[h\left([f_j(X_i)-f_j(X_i')]_{1\leq j\leq m, \;1\leq i\leq n} \right)\right] = \mathbb{E}\left[h\left(\left[\epsilon_i(f_j(X_i)-f_j(X_i'))\right]_{1\leq j\leq m, \;1\leq i\leq n} \right)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5Cleft%5Bh%5Cleft%28%5Bf_j%28X_i%29-f_j%28X_i%27%29%5D_%7B1%5Cleq+j%5Cleq+m%2C+%5C%3B1%5Cleq+i%5Cleq+n%7D+%5Cright%29%5Cright%5D+%3D+%5Cmathbb%7BE%7D%5Cleft%5Bh%5Cleft%28%5Cleft%5B%5Cepsilon_i%28f_j%28X_i%29-f_j%28X_i%27%29%29%5Cright%5D_%7B1%5Cleq+j%5Cleq+m%2C+%5C%3B1%5Cleq+i%5Cleq+n%7D+%5Cright%29%5Cright%5D&bg=ffffff&fg=000000&s=0&c=20201002) .
. .
.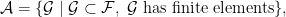
![\displaystyle \begin{aligned} \mathbb{E}\left [ \sup_{f\in \mathcal{F}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right] := \sup_{\mathcal{G}\in \mathcal{A}} \mathbb{E}\left [ \sup_{f\in \mathcal{G}} \frac{1}{n}\sum_{i=1}^n \left( f(X_i) - \mathbb{E}(f(X_i) \right) \right]. \end{aligned} \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BF%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D+%3A%3D+%5Csup_%7B%5Cmathcal%7BG%7D%5Cin+%5Cmathcal%7BA%7D%7D+%5Cmathbb%7BE%7D%5Cleft+%5B+%5Csup_%7Bf%5Cin+%5Cmathcal%7BG%7D%7D+%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Cleft%28+f%28X_i%29+-+%5Cmathbb%7BE%7D%28f%28X_i%29+%5Cright%29+%5Cright%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
 on real line
on real line 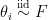 where
where  and
and 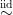 means “independently and identically distributed as”. We denote
means “independently and identically distributed as”. We denote 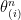 to be the
to be the  -th largest random variable of the
-th largest random variable of the 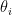 s. So
s. So 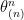 is the largest value and
is the largest value and  is the smallest of the
is the smallest of the  s. Note here the subscript
s. Note here the subscript  does not mean taking to the
does not mean taking to the  are called order statistics in Statistics. They are
are called order statistics in Statistics. They are  ,
,  and
and 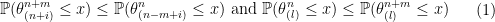

 -th largest value. The left inequalities of the inequality
-th largest value. The left inequalities of the inequality  -th order statistic is in expectation.
-th order statistic is in expectation.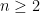 and take
and take 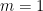 ,
,  , and
, and 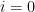 in Theorem
in Theorem 
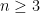 , then we can take
, then we can take 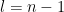 ,
,  . Then equation
. Then equation 
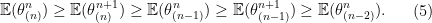
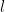 and
and 
 and
and  are interlacing. The main idea of the proof is putting
are interlacing. The main idea of the proof is putting 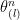 and
and  and
and  in the same probability space and arguing that we actually have almost sure inequality instead of just expectation or stochastically dominance. This technique is known as coupling.
in the same probability space and arguing that we actually have almost sure inequality instead of just expectation or stochastically dominance. This technique is known as coupling.  follows
follows 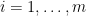 . We now consider all the
. We now consider all the 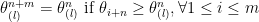

 -th largest value
-th largest value  is always smaller than the
is always smaller than the 

 have joint distribution
have joint distribution  . Denote
. Denote  to be the order statistics. Now consider only the first
to be the order statistics. Now consider only the first 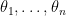 . Denote their marginal distribution as
. Denote their marginal distribution as 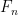 . We denote the order statistics of these
. We denote the order statistics of these  . Then for any
. Then for any  and
and 
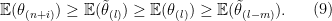
 and order them so that we have
and order them so that we have  s. Now if we generate the extra
s. Now if we generate the extra  and the first
and the first 
 is at most
is at most 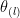 since we have
since we have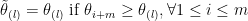

 s, the
s, the  is always smaller than the
is always smaller than the 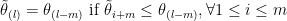

 for any
for any 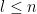 .
.  with parameter (index)
with parameter (index)  is said to be a natural exponential family if
is said to be a natural exponential family if 
 , we call
, we call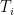 : natural sufficient statistic
: natural sufficient statistic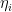 : natural parameter
: natural parameter : natural parameter space.
: natural parameter space.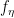 ,
, 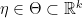 , and a random variable
, and a random variable  , a statistic
, a statistic 
 is independent of
is independent of  . A sufficient statistic
. A sufficient statistic  , there is a function
, there is a function  such that
such that  .
. ! So even though you don’t know the underlying distribution
! So even though you don’t know the underlying distribution  is
is .
.
 .
.
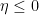 for the integral
for the integral  to be finite and
to be finite and  for the integral
for the integral  to be finite. This means actually
to be finite. This means actually  and so the natural parameter space is a single point
and so the natural parameter space is a single point  .
. is indeed sufficient. But any constant estimator is also sufficient and minimal as any other sufficient statistic under a constant function is a constant. But
is indeed sufficient. But any constant estimator is also sufficient and minimal as any other sufficient statistic under a constant function is a constant. But  , if
, if  , i.e.,
, i.e., 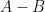 is nonnegative as well, is there any relation with their singular values?
is nonnegative as well, is there any relation with their singular values?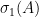 , is larger than the largest singular value of
, is larger than the largest singular value of 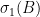 :
: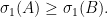
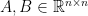 are symmetric, so that
are symmetric, so that 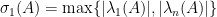 ,
,  . Here for any symmetric matrix
. Here for any symmetric matrix  , we denote its eigenvalues as
, we denote its eigenvalues as  .
. are all nonnegative and symmetric, then
are all nonnegative and symmetric, then 
 corresponding to the eigenvalue
corresponding to the eigenvalue 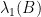 , which is both nonnegative and largest in magnitude. Next, by multiplying left and right of
, which is both nonnegative and largest in magnitude. Next, by multiplying left and right of 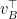 and
and 
 . The step
. The step  . The step
. The step  are symmetric and both are nonnegative so largest eigenvalue is indeed just the singular value due to Perron-Frobenius theorem.
are symmetric and both are nonnegative so largest eigenvalue is indeed just the singular value due to Perron-Frobenius theorem. 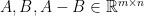 are all nonnegative, then
are all nonnegative, then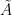 and
and  in
in  :
:
 , we also have
, we also have 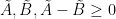 . Using Lemma
. Using Lemma  in this case by considering
in this case by considering
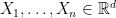 , how do you test that
, how do you test that  , i.e., a set
, i.e., a set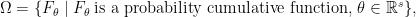
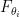 for some
for some 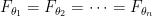 ?
? (known as the identifiability of
(known as the identifiability of 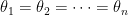 ?
?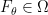 has a density
has a density  is
is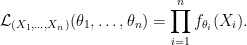


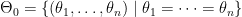 and the space of the alternative as
and the space of the alternative as 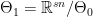 . A popular and natural approach is the likelihood ratio test. We construct the test statistic which is called likelihood ratio as
. A popular and natural approach is the likelihood ratio test. We construct the test statistic which is called likelihood ratio as 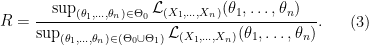
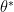 such that
such that  and
and 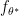 , then this ratio should be large and we have confidence that our null hypothesis is true. This means we should reject our null hypothesis if we find
, then this ratio should be large and we have confidence that our null hypothesis is true. This means we should reject our null hypothesis if we find  is small. Thus if we want to have a significance level
is small. Thus if we want to have a significance level  test of our null hypothesis, we should reject null hypothesis when
test of our null hypothesis, we should reject null hypothesis when  where
where  satisfies
satisfies 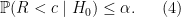
 even if we know how to sample from each
even if we know how to sample from each 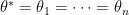 ) generates the data. So the distribution of
) generates the data. So the distribution of 
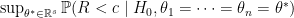 through computational methods, we have to simulate for each
through computational methods, we have to simulate for each 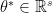 . As
. As  could be rather large (in fact as large as
could be rather large (in fact as large as  ), approximation can be time consuming as well.
), approximation can be time consuming as well. is the so called location-scale family, we find that the distribution of
is the so called location-scale family, we find that the distribution of 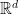 indexed by
indexed by 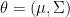 where
where  and
and  , the set of invertible matrices in
, the set of invertible matrices in  . The family
. The family 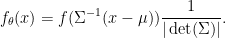
 follows
follows 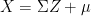 has probability density
has probability density  . Indeed, for any Borel set
. Indeed, for any Borel set 
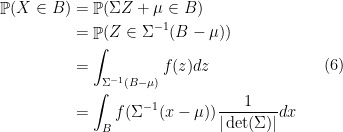
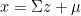 in the last equality and the last equality shows
in the last equality and the last equality shows 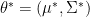 such that each
such that each 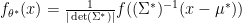 and the distribution of
and the distribution of 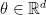 , and any
, and any 
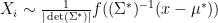 and
and  where
where 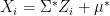 . Then the likelihood of
. Then the likelihood of 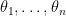 is
is 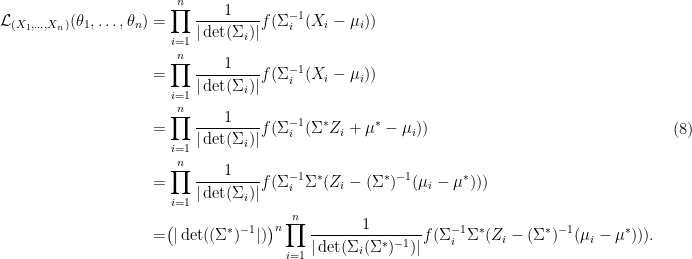

 ,
,  ,
,  and
and 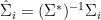 . Note that since
. Note that since 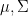 ,
,  can vary all over the space
can vary all over the space 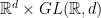 , so is
, so is 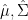 ,
, 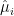 and
and 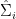 . The equality
. The equality 
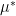 and
and 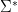 at all. So our theorem is proved.
at all. So our theorem is proved. 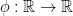 , a convex function
, a convex function 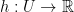 where
where 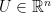 is a convex set and an
is a convex set and an 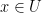 , if
, if  or
or  , then
, then![\displaystyle \begin{aligned} \partial (\phi \circ h) (x) = \phi' (h(x)) \cdot[ \partial h (x)], \end{aligned} \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%5Cpartial+%28%5Cphi+%5Ccirc+h%29+%28x%29+%3D+%5Cphi%27+%28h%28x%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D%2C+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
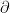 is the operator of taking subdifferentials of a function, i.e.,
is the operator of taking subdifferentials of a function, i.e., 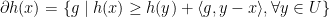 for any
for any 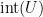 is the interior of
is the interior of  with respect to the standard topology in
with respect to the standard topology in 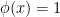 for all
for all 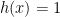 defined on
defined on ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then
. Then ![{[0,1],\phi'(0) = 0}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%2C%5Cphi%27%280%29+%3D+0%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, ![{\partial h(0) =(-\infty,0]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+h%280%29+%3D%28-%5Cinfty%2C0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . However, in this case
. However, in this case ![{\partial (\phi\circ h)(0)= (-\infty,0]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+%28%5Cphi%5Ccirc+h%29%280%29%3D+%28-%5Cinfty%2C0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) and
and ![{\phi' (h(0)) \cdot[ \partial h (0)] =0}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%27+%28h%280%29%29+%5Ccdot%5B+%5Cpartial+h+%280%29%5D+%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Thus, the equality fails.
. Thus, the equality fails.![{\partial (\phi \circ h) (x) \supset \phi' (h(x)) \cdot[ \partial h (x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+%28%5Cphi+%5Ccirc+h%29+%28x%29+%5Csupset+%5Cphi%27+%28h%28x%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We have for all
. We have for all  ,
,
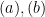 are just the definition of subdifferential of
are just the definition of subdifferential of  at
at  and
and  in the inequality
in the inequality 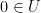 such that
such that 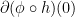 is not empty. Let
is not empty. Let 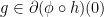 , we wish to show that
, we wish to show that ![{ \phi' (h(0)) \cdot[ \partial h (0)]}](https://s0.wp.com/latex.php?latex=%7B+%5Cphi%27+%28h%280%29%29+%5Ccdot%5B+%5Cpartial+h+%280%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . First according to the definition of subdifferential, we have
. First according to the definition of subdifferential, we have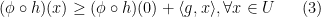
![\displaystyle \begin{aligned} (\phi \circ h) (\gamma x)\geq (\phi\circ h)(0) + \langle{ g} ,{\gamma x}\rangle, \forall x \in U, \gamma \in [0,1]. \end{aligned} \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Baligned%7D+%28%5Cphi+%5Ccirc+h%29+%28%5Cgamma+x%29%5Cgeq+%28%5Cphi%5Ccirc+h%29%280%29+%2B+%5Clangle%7B+g%7D+%2C%7B%5Cgamma+x%7D%5Crangle%2C+%5Cforall+x+%5Cin+U%2C+%5Cgamma+%5Cin+%5B0%2C1%5D.+%5Cend%7Baligned%7D+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
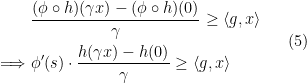
 between
between 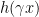 and
and 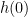 by mean value theorem. Now, by letting
by mean value theorem. Now, by letting 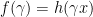 , if
, if  is nondecreasing in
is nondecreasing in 
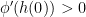 , then dividing both sides of the above inequality by
, then dividing both sides of the above inequality by 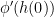 gives
gives 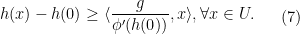
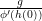 is indeed a member of
is indeed a member of 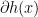 and thus
and thus ![{\partial (\phi \circ h) (x) \subset \phi' (h(x)) \cdot[ \partial h (x)]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial+%28%5Cphi+%5Ccirc+h%29+%28x%29+%5Csubset+%5Cphi%27+%28h%28x%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . In this case, we only need to verify why
. In this case, we only need to verify why 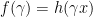 must be right continuous at
must be right continuous at 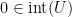 , then
, then 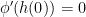 , using the inequality
, using the inequality 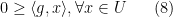
 , then
, then 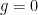 and it indeed belongs to the set
and it indeed belongs to the set ![{\phi' (h(0)) \cdot[ \partial h (x)] = \{0\}}](https://s0.wp.com/latex.php?latex=%7B%5Cphi%27+%28h%280%29%29+%5Ccdot%5B+%5Cpartial+h+%28x%29%5D+%3D+%5C%7B0%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as  for
for 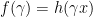 is indeed right continuous at
is indeed right continuous at  exists and
exists and  . Now if
. Now if  , then
, then 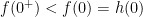 . But in this case
. But in this case 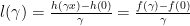 is going to be negative infinity as
is going to be negative infinity as  . Recall from inequality
. Recall from inequality 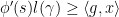
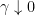 ,
, 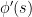 approaches a positive number. If this claim is true, then from the above inequality, we will have
approaches a positive number. If this claim is true, then from the above inequality, we will have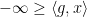
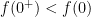 . Using mean value theorem, we have for some
. Using mean value theorem, we have for some ![{s_0 \in [ f(0^+), f(0)]}](https://s0.wp.com/latex.php?latex=%7Bs_0+%5Cin+%5B+f%280%5E%2B%29%2C+f%280%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
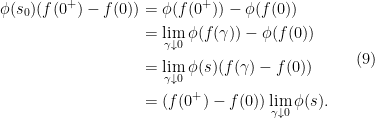
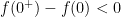 above, we see that
above, we see that  . We claim
. We claim 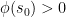 . If
. If 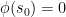 , then because
, then because ![{[f(0^+),f(0)]}](https://s0.wp.com/latex.php?latex=%7B%5Bf%280%5E%2B%29%2Cf%280%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) as
as 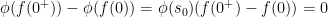 . This contradicts our assumption that
. This contradicts our assumption that  and our proof is complete.
and our proof is complete. ![{f:[0,1]\rightarrow \mathbb{R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5B0%2C1%5D%5Crightarrow+%5Cmathbb%7BR%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) be a (strictly) convex function, then the function
be a (strictly) convex function, then the function ![{g(x) = \frac{f(x)-f(0)}{x}, x\in(0,1]}](https://s0.wp.com/latex.php?latex=%7Bg%28x%29+%3D+%5Cfrac%7Bf%28x%29-f%280%29%7D%7Bx%7D%2C+x%5Cin%280%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is non-decreasing (strictly increasing).
is non-decreasing (strictly increasing). 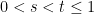
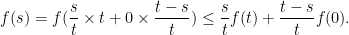
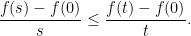
 by
by 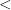 .
.  where
where  is any connected set in
is any connected set in 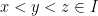 , we have
, we have
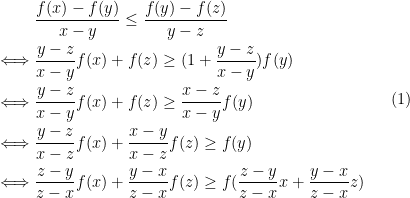
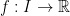 where
where ![{[a,b],(a,b),(a,b],[a,b)}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%2C%28a%2Cb%29%2C%28a%2Cb%5D%2C%5Ba%2Cb%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) where
where  . Then
. Then 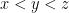 all in
all in 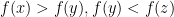
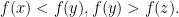
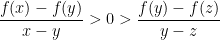
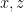 are interior point of
are interior point of ![{[x,z]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2Cz%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This means that
. This means that 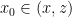 as
as 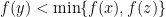 . Now for any
. Now for any 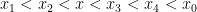 , by convexity and monotonicity of slope, we have
, by convexity and monotonicity of slope, we have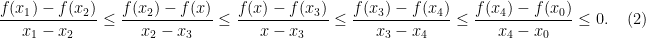
 . Thus
. Thus ![{I\cap (-\infty,x_0]}](https://s0.wp.com/latex.php?latex=%7BI%5Ccap+%28-%5Cinfty%2Cx_0%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Similarly, using monotonicity of slope, we have
. Similarly, using monotonicity of slope, we have 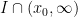 . Now if suppose either
. Now if suppose either  is the end point of
is the end point of  . Then there are only three possible cases
. Then there are only three possible cases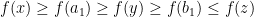
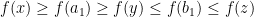

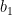 are interior point and we can proceed our previous argument and show
are interior point and we can proceed our previous argument and show 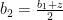 and ask the relation between
and ask the relation between 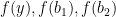 and
and  . The only non-ideal case is that
. The only non-ideal case is that  (the other case gives three interior point such that
(the other case gives three interior point such that  and we can employ our previous argument). We can then further have
and we can employ our previous argument). We can then further have  . Again there will be only one non-ideal case that
. Again there will be only one non-ideal case that  .
.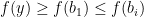 or the sequence
or the sequence  satisfies
satisfies  for all
for all 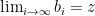 . If
. If 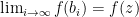 . But this is not possible because
. But this is not possible because 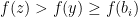 . Thus
. Thus  . Indeed, for any
. Indeed, for any 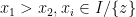 for
for  , there is a
, there is a 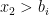 and so
and so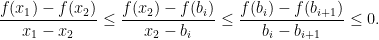
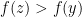 , we see
, we see ![{f:[a,b] \rightarrow \mathbb{R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5Ba%2Cb%5D+%5Crightarrow+%5Cmathbb%7BR%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is convex for some
is convex for some 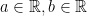 . Then
. Then 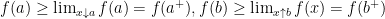 .
. 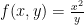 on
on 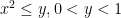 and the point
and the point 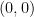 .
.