Suppose we have a random vector 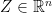



Previously, we showed in this post that as long as
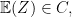
if 
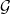

The answer is affirmative. Let us first recall our previous theorem.
Theorem 1 For any borel measurable convex set
, and for any probability measure
on
with
we have

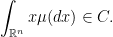
By utilizing the above theorem and regular conditional distribution, we can prove our previous claim.
Theorem 2 Suppose
to
is the usual Borel sigma algebra on
. If
then we have
for any sigma algebra
.


Proof: Since 
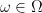
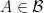

and for any real valued borel function 
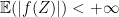
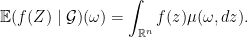
The above two actually comes from the existence of regular conditional distribution which is an important result in measure-theoretic probability theory.
Now take 



and
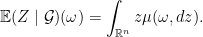
But since 
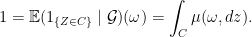
Thus for almost all 
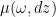

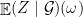

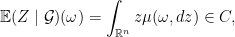
for almost all

